
- Resources
- https://cloud.google.com/blog/products/devops-sre/sre-at-google-our-complete-list-of-cre-life-lessons
- Books
- The Site Reliability
- Site Reliability Engineering
- https://sre.google/sre-book/table-of-contents/
- Effective Devops
- https://www.oreilly.com/library/view/effective-devops/9781491926291/
- The Phoenix Project
- The Practice of Cloud System Administration: DevOps and SRE Practices for Web Services, Volume2
- https://www.amazon.com/Practice-Cloud-System-Administration-Practices/dp/032194318X/ref=sr_1_1?ie=UTF8&qid=1527184188&sr=8-1&keywords=practice+of+cloud+system+administration
- Accelerate: The Science of Lean Software and DevOps
- https://www.amazon.com/Accelerate-Software-Performing-Technology-Organizations/dp/1942788339/ref=sr_1_2?ie=UTF8&qid=1515161455&sr=8-2&keywords=accelerate
- https://www.squadcast.com/blog/must-read-devops-sre-books-for-all-engineers
- The Phoenix Project

- Bonus: Beyond The Phoenix Project is a podcast where the practices mentioned in the book are discussed more deeply
- The Unicorn Project
- The Goal: A Process of Ongoing Improvement
- Effective DevOps
- Site Reliability Engineering
- Practical DevOps
- Real World SRE
- Accelerate: Building & Scaling High Performing Technology Organization
- Seeking SRE: Conversations About Running Production Systems at Scale
- A Seat at the Table: IT Leadership in the Age of Agility
- The Human Side of Postmortems
- Thinking in Systems
- The Phoenix Project
- https://realtoughcandy.com/sre-books/
- Site Reliability Engineering: How Google Runs Production Systems
- The Site Reliability Workbook
- Building Secure and Reliable Systems
- The Practice of Cloud System Administration
- Chaos Engineering: System Resiliency in Practice
- Real-World SRE
- Chaos Engineering: Site Reliability Through Controlled Disruption
- Hands-On Site Reliability Engineering
- Seeking SRE
- SRE with Java Microservices
- 97 Things Every SRE Should Know
- Chaos Engineering
- Serverless Architectures on AWS 2nd edition
- Software Telemetry
- Site Reliability Engineering: How Google Runs Production Systems
































Books
The Site Reliability Book
In a devops approach, you improve something (often by automating it), measure the results and share those results with colleagues so the whole organization can improve.
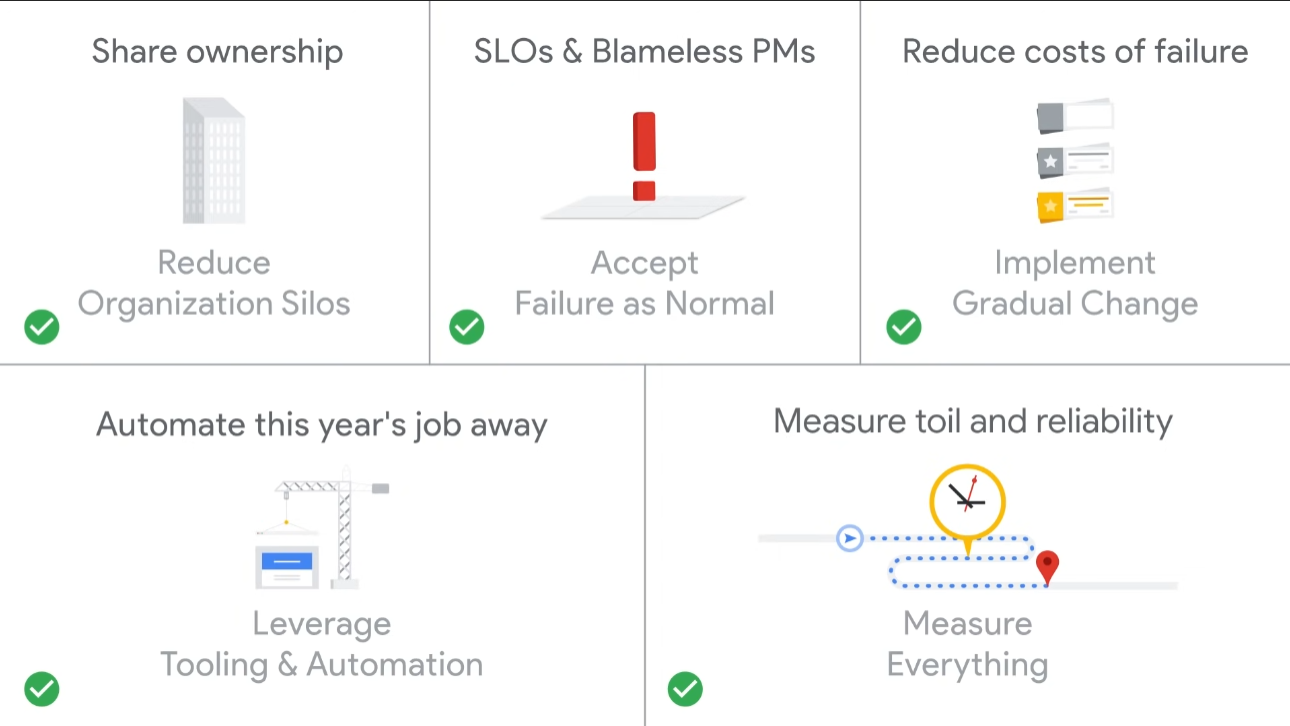
- No more silos
- The first key idea is o more silos. This is a reaction to a couple ideas:
- The historically popular but now increasingly old-fashioned arrangement of separate operations and development teams
- The fact that extreme siliozation of knowledge, incentives for purely local optimization, and lack of collaboration have in many cases been actively bad for business.
- The first key idea is o more silos. This is a reaction to a couple ideas:
- Change Should be Gradual
- Build a steady pipeline of low-risk change out of regular output from product, design, and infrastructure changes. This strategy, coupled with automatic testing of smaller changes and reliable rollback of bad changes, leads to approaches to change management like CI/CD.
- Tooling and Culture are Interrelated
- A good culture can work around broken tooling, but the opposite rarely holds true.
- Measurement is Crucial
class SRE implements interface DevOps
- Operations is a Software Problem
- Manage by Service Level Objectives (SLOs)
- Work to minimize Toil
- Automate This Year’s Job Away
- Move Fast by Reducing the Cost of Failure
- reduced mean time to repair (MTTR)
- Share ownership with developers
- SREs tend to be inclined to focus on production problems rather than business logic problems, but as their approach brings software engineering tools to bear on the problem, they share skill sets with product development teams.
- In general, SRE has particular expertise around the availability, latency, performance, efficiency, change management, monitoring, emergency response, and capacity planning of the service(s) they are looking after.
- Use the same tooling, regardless of function or job title
Youtube
Inmetrics
Eduardo Maldonado




Fabio Reginaldo (Quode)

- SRE Foundation Course: Value Added Resources
- 1: SRE Principles & Practices
- ‘What’s the Difference Between DevOps and SRE?’ with Seth Vargo and Liz Fong-Jones of Google (05:10)
- https://youtu.be/uTEL8Ff1Zvk
- ‘What’s the Difference Between DevOps and SRE?’ with Seth Vargo and Liz Fong-Jones of Google (05:10)
- 2: Service Level Objectives & Error Budgets
- ‘Risk and Error Budgets’ with Seth Vargo and Liz Fong-Jones of Google (06:17)
- https://youtu.be/y2ILKr8kCJU
- ‘Risk and Error Budgets’ with Seth Vargo and Liz Fong-Jones of Google (06:17)
- 3: Reducing Toil
- ‘Pragmatic Automation’ with Max Luebbe of GCP (04:45)
- https://www.youtube.com/watch?v=oDcjAcFTFC0&t=0m56s
- ‘Pragmatic Automation’ with Max Luebbe of GCP (04:45)
- 4: Monitoring & Service Level Indicators
- ‘SLI & Reliability Deep-Dive’ with David N. Blank-Edelman of Microsoft (08:35)
- https://www.youtube.com/watch?v=1iMo3SkdQqQ
- ‘SLI & Reliability Deep-Dive’ with David N. Blank-Edelman of Microsoft (08:35)
- 5: SRE Tools & Automation
- ‘Ironies of Automation: A Comedy in Three Parts’ with Tanner Lund of Microsoft (18:32)
- https://www.youtube.com/watch?v=U3ubcoNzx9k
- ‘Ironies of Automation: A Comedy in Three Parts’ with Tanner Lund of Microsoft (18:32)
- 6: Anti-Fragility & Learning from Failure
- ‘Sloth, a Tool for Inducing Network Failures’ with Preetha Appan of Indeed.com (04:45)
- https://www.usenix.org/conference/srecon17americas/program/presentation/appan
- ‘Sloth, a Tool for Inducing Network Failures’ with Preetha Appan of Indeed.com (04:45)
- 7: Organizational Impact of SRE
- ‘A History of SRE at Uber’ with Rick Boone of Uber (06:24)
- https://www.youtube.com/watch?v=qJnS-EfIIIE
- ‘A History of SRE at Uber’ with Rick Boone of Uber (06:24)
- 8: SRE, Other Frameworks, Trends
- ‘A Look at ITIL4 & SRE’ with Jayne Groll of DevOps Institute (11:25)
- https://dev.tube/video/vFyPXIsUEhE
- ‘A Look at ITIL4 & SRE’ with Jayne Groll of DevOps Institute (11:25)
- 1: SRE Principles & Practices
- SRE Reports
- 2019 SRE Report
- Catchpoint
- http://pages.catchpoint.com/SRE-Report-2019.html
- Catchpoint
- What is SRE?
- Kurt Andersen & Craig Sebenik from O’Reilly Media
- https://www.oreilly.com/library/view/what-is-sre/9781492054429/
- Kurt Andersen & Craig Sebenik from O’Reilly Media
- 2019 SRE Report
- SRE Articles
- ‘Which Factors Affect Software Projects Maintenance Cost More?’ by Sayed Mehdi Hejazi Dehaghani and Nafiseh Hajrahimi
- 1: SRE Principles & Practices
- https://www.ncbi.nlm.nih.gov/pmc/articles/PMC3610582/
- 1: SRE Principles & Practices
- ‘Measuring and Evaluating Service Level Objectives (SLOs)’ by Serhat Can
- 1: SRE Principles & Practices
- https://medium.com/@serhatcan/measuring-and-evaluating-service-level-objectives-slos-84b0dc740a0a

- https://www.datadoghq.com/blog/set-and-monitor-slas/
- https://medium.com/@serhatcan/measuring-and-evaluating-service-level-objectives-slos-84b0dc740a0a
- 1: SRE Principles & Practices
- ‘Bloomberg Bets Big on SREs’ by Michael Rembetsy
- 1: SRE Principles & Practices
- https://www.techatbloomberg.com/blog/bloomberg-bets-big-on-sres/
- 1: SRE Principles & Practices
- ‘Site Reliability Engineering at Bloomberg’ by Stig Sorensen
- 1: SRE Principles & Practices
- https://player.fm/series/devops-chat/site-reliability-engineering-sre-bloomberg-w-stig-Sorenson
- 1: SRE Principles & Practices
- ‘What It Means To Be A Site Reliability Engineer’ by Molly Struve
- 1: SRE Principles & Practices
- https://dev.to/molly_struve/what-it-means-to-be-a-site-reliability-engineer-32ki
- 1: SRE Principles & Practices
- ‘Error Budgets – Practical Implementation’ by Yaroslav Molochko
- 2: SLO’s & Error Budgets
- https://www.slideshare.net/yaroslavmolochko/implementing-error-budgets-125400822
- 2: SLO’s & Error Budgets
- ‘How to Avoid the 5 SRE Implementation Traps that Catch Even the Best Teams’ by Lyon Wong
- 2: SLO’s & Error Budgets
- https://thenewstack.io/how-to-avoid-the-5-sre-implementation-traps-that-catch-even-the-best-teams/
- 2: SLO’s & Error Budgets
- ‘Site Reliability Engineering: DevOps 2.0’ by Saba Anees
- 2: SLO’s & Error Budgets
- https://www.appdynamics.com/blog/engineering/site-reliability-engineering-devops-2-0/
- 2: SLO’s & Error Budgets
- ‘Getting Started with Site Reliability Engineering’ by Jennifer Petoff
- 2: SLO’s & Error Budgets
- https://www.devops.talksplus.com/wp-content/themes/dotc/2019_Melbourne/presentations/Getting%20Started%20with%20Site%20Reliability%20Engineering%20(Jennifer%20Petoff%20DOTC%20Deck).pdf
- 2: SLO’s & Error Budgets
- ‘Invent More, Toil Less’ by Betsy Beyer, Brendan Gleason, Dave O’connor and Vivek Rau
- 3: Reducing Toil
- https://storage.googleapis.com/pub-tools-public-publication-data/pdf/45765.pdf
- 3: Reducing Toil
- ‘SRE Lessons: Continuously Optimize to Reduce Toil’ by Damon Edwards
- 3: Reducing Toil
- https://www.rundeck.com/blog/sre-lessons-continuously-optimize-to-reduce-toil
- 3: Reducing Toil
- ‘Toil: Finally a Name For a Problem We’ve All Felt’ by Damon Edwards
- 3: Reducing Toil
- https://www.rundeck.com/blog/toil-finally-a-name-for-a-problem
- 3: Reducing Toil
- ‘SRE Lessons: Continuously Optimize to Reduce Toil’ by Damon Edwards
- 3: Reducing Toil
- https://www.rundeck.com/blog/sre-lessons-continuously-optimize-to-reduce-toil
- 3: Reducing Toil
- ‘Site Reliability Engineering (SRE): A Simple Overview’ by Mac Slocum
- 3: Reducing Toil
- https://www.oreilly.com/ideas/site-reliability-engineering-sre-a-simple-overview
- 3: Reducing Toil
- ‘What Is SRE?’ by Craig Sebenik & Kurt Andersen
- 3: Reducing Toil
- https://www.oreilly.com/library/view/what-is-sre/9781492054429/
- 3: Reducing Toil
- ‘Is It Worth the Time?’ by Xkcd
- 3: Reducing Toil
- https://imgs.xkcd.com/comics/is_it_worth_the_time.png
- 3: Reducing Toil
- ‘An Engineer’s Guide To SLA, SLO, and SLI’ by Ram Lyengar
- 4: Monitoring & Service Level Indicators
- https://plumbr.io/blog/monitoring/an-engineers-guide-to-sla-slo-and-sli
- 4: Monitoring & Service Level Indicators
- ‘Service Level Indicators in Practice’ by Stephen Thorne
- 4: Monitoring & Service Level Indicators
- https://medium.com/@jerub/service-level-indicators-in-practice-6a1125e24bee
- 4: Monitoring & Service Level Indicators
- ‘Stop Using Nagios (So It Can Die Peacefully)’ by Andy Sykes
- 4: Monitoring & Service Level Indicators
- http://www.slideshare.net/superdupersheep/stop-using-nagios-so-it-can-die-peacefully
- 4: Monitoring & Service Level Indicators
- ‘Why Does (My) Monitoring Suck?’ by Todd Palion
- 4: Monitoring & Service Level Indicators
- https://www.usenix.org/conference/srecon19asia/presentation/palino-monitoring
- 4: Monitoring & Service Level Indicators
- ‘Observability — A 3-Year Retrospective’ by Charity Majors
- 4: Monitoring & Service Level Indicators
- https://thenewstack.io/observability-a-3-year-retrospective/
- 4: Monitoring & Service Level Indicators
- ‘Monitoring and Observability — What’s the Difference and Why Does It Matter?’ by Peter Waterhouse
- 4: Monitoring & Service Level Indicators
- https://thenewstack.io/monitoring-and-observability-whats-the-difference-and-why-does-it-matter/
- 4: Monitoring & Service Level Indicators
- ‘3 Ways to Reduce Alert Noise in Monitoring’ by Christina DiSomma
- 4: Monitoring & Service Level Indicators
- https://www.metricly.com/3-ways-reduce-alert-noise/
- 4: Monitoring & Service Level Indicators
- ‘Observability and Understanding the Operational Ramifications of a System’ by Charity Majors
- 4: Monitoring & Service Level Indicators
- https://www.infoq.com/articles/charity-majors-observability-failure/
- 4: Monitoring & Service Level Indicators
- ‘Run a Service Level Indicator (SLI) workshop’ BY GDS
- 4: Monitoring & Service Level Indicators
- https://gds-way.cloudapps.digital/standards/slis.html
- 4: Monitoring & Service Level Indicators
- ‘The Evolution of Automation at Google’ by Niall Murphy
- 5: SRE Tools & Automation
- https://landing.google.com/sre/sre-book/chapters/automation-at-google/
- 5: SRE Tools & Automation
- ‘SRE at the Department for Work and Pensions’ by various
- 5: SRE Tools & Automation
- https://dwpdigital.blog.gov.uk/category/site-reliability-engineering-sre/
- 5: SRE Tools & Automation
- ‘Measuring and Evaluating Service Level Objectives (SLOs)’ by Serhat Can
- 5: SRE Tools & Automation
- https://www.atlassian.com/blog/opsgenie/measuring-and-evaluating-service-level-objectives
- 5: SRE Tools & Automation
- ‘Best NoSQL Databases 2019’
- 5: SRE Tools & Automation
- https://www.improgrammer.net/most-popular-nosql-database/
- 5: SRE Tools & Automation
- ‘On-Call Tools to Support a DevOps Culture’ by Dan Holloran
- 5: SRE Tools & Automation
- https://victorops.com/blog/devops-on-call-tools-to-support-culture
- 5: SRE Tools & Automation
- ‘Awesome Site Reliability Engineering Tools’ by Raghu Chinnannan
- 5: SRE Tools & Automation
- https://github.com/squadcastHQ/awesome-sre-tools
- 5: SRE Tools & Automation
- ‘Security & Compliance’ by Ansible
- 5: SRE Tools & Automation
- https://www.ansible.com/use-cases/security-and-compliance
- 5: SRE Tools & Automation
- ‘Secure Coding Best Practices’ by OWASP
- 5: SRE Tools & Automation
- https://www.owasp.org/images/0/08/OWASP_SCP_Quick_Reference_Guide_v2.pdf
- 5: SRE Tools & Automation
- ‘Testing in Production, the safe way’ by Cindy Sridharan
- 5: SRE Tools & Automation
- https://medium.com/@copyconstruct/testing-in-production-the-safe-way-18ca102d0ef1
- 5: SRE Tools & Automation
- ‘Amazon Andon Cord: What it is and how to react’ by Velentin Bayard
- 5: SRE Tools & Automation
- https://blueboard.io/resources/amazon-andon-cord/
- 5: SRE Tools & Automation
- ‘DevOps Tools Landscape’ by GitLab
- 5: SRE Tools & Automation
- https://about.gitlab.com/devops-tools/
- 5: SRE Tools & Automation
- ‘Measure Efficiency, Effectiveness, and Culture to Optimize DevOps Transformations’ by IT Revolution
- 6: Antifragility & Learning from Failure
- http://devopsenterprise.io/media/DOES_forum_metrics_102015.pdf
- 6: Antifragility & Learning from Failure
- ‘Tracking Every Release’ by Mike Brittain
- 6: Antifragility & Learning from Failure
- https://codeascraft.com/2010/12/08/track-every-release/
- 6: Antifragility & Learning from Failure
- ‘A recovery point objective (RPO)’ by Margaret Rouse
- 6: Antifragility & Learning from Failure
- https://whatis.techtarget.com/definition/recovery-point-objective-RPO
- 6: Antifragility & Learning from Failure
- ‘The Learning Organization’ by Andrew Shafer
- 6: Antifragility & Learning from Failure
- https://www.slideshare.net/littleidea/the-learning-organization-modev
- 6: Antifragility & Learning from Failure
- ‘The Three Ways: The Principles Underpinning DevOps’ by Gene Kim
- 6: Antifragility & Learning from Failure
- https://itrevolution.com/the-three-ways-principles-underpinning-devops/
- 6: Antifragility & Learning from Failure
- ‘A Typology of Organizational Cultures’ by R Westrum
- 6: Antifragility & Learning from Failure
- http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1765804/pdf/v013p0ii22.pdf
- 6: Antifragility & Learning from Failure
- ‘Do You Want Your Cloud Solutions to Succeed? Start with Embracing Failures!’ by Arman Kamran
- 6: Antifragility & Learning from Failure
- https://medium.com/@armankamran/do-you-want-your-cloud-solutions-to-succeed-start-with-embracing-failures-8f5f40b57a64
- 6: Antifragility & Learning from Failure
- ‘The Cost of IT Downtime’ by Michael Copeland
- 7: Organizational impact of SRE
- https://www.the20.com/blog/the-cost-of-it-downtime/
- 7: Organizational impact of SRE
- ‘How SRE teams are organized, and how to get started’ by Matt Brown
- 7: Organizational impact of SRE
- https://cloud.google.com/blog/products/devops-sre/how-sre-teams-are-organized-and-how-to-get-started
- 7: Organizational impact of SRE
- ‘Kubernetes Up & Running’ by Brendan Burns, Joe Beda & Kelsey Hightower
- 7: Organizational impact of SRE
- https://clouddamcdnprodep.azureedge.net/gdc/gdckTlBtc/original
- 7: Organizational impact of SRE
- ‘Blameless PostMortems and a Just Culture’ by John Allspaw
- 7: Organizational impact of SRE
- https://codeascraft.com/2012/05/22/blameless-postmortems/
- 7: Organizational impact of SRE
- ‘The Prime Directive’ by Norm Kerth
- 7: Organizational impact of SRE
- https://retrospectivewiki.org/index.php?title=The_Prime_Directive
- 7: Organizational impact of SRE
- ‘Creating Antifragile Systems: Site Reliability Engineering for the Enterprise’ by Contino
- 7: Organizational impact of SRE
- https://www.contino.io/files/Enterprise-Site-Reliability-Engineering-Contino.pdf
- 7: Organizational impact of SRE
- ‘Scaling SRE Organizations: The journey from 1 to many teams’ by Gustavo Franco
- 7: Organizational impact of SRE
- https://www.usenix.org/sites/default/files/conference/protected-files/sre19amer_slides_franco.pdf
- 7: Organizational impact of SRE
- ‘The Convergence of DevOps’ by John Willis
- 8: SRE, Other Frameworks, Trends
- http://itrevolution.com/the-convergence-of-devops/
- 8: SRE, Other Frameworks, Trends
- ‘Site Reliability Engineer (SRE) Roles and Responsibilities’ by Dan Holloran
- 8: SRE, Other Frameworks, Trends
- https://victorops.com/blog/site-reliability-engineer-sre-roles-and-responsibilities
- 8: SRE, Other Frameworks, Trends
- ‘How ITIL4 and SRE align with DevOps’ by Jayne Groll
- 8: SRE, Other Frameworks, Trends
- https://techbeacon.com/enterprise-it/how-itil4-sre-align-devops
- 8: SRE, Other Frameworks, Trends
- ‘Future of Reliability Engineering’ by Michael Kehoe
- 8: SRE, Other Frameworks, Trends
- https://michael-kehoe.io/tags/future-of-sre/
- 8: SRE, Other Frameworks, Trends
- ‘An Introduction to Database Reliability’ by Mackenzie Clark
- 8: SRE, Other Frameworks, Trends
- https://softwareengineeringdaily.com/2018/10/16/an-introduction-to-database-reliability/
- 8: SRE, Other Frameworks, Trends
- ‘Stop the Arguments: ITIL v4 and SRE and DevOps All Are Transformation Aids’
- 8: SRE, Other Frameworks, Trends
- https://devopsinstitute.com/2019/11/05/stop-the-arguments-itil-v4-and-sre-and-devops-all-are-transformation-aids/
- 8: SRE, Other Frameworks, Trends
- ‘Which Factors Affect Software Projects Maintenance Cost More?’ by Sayed Mehdi Hejazi Dehaghani and Nafiseh Hajrahimi
- Websites
- Usenix
- https://www.usenix.org/
- Honeycomb
- https://www.honeycomb.io/
- Player FM - Devops Chart
- https://player.fm/series/devops-chat
- SRE Weekly
- https://sreweekly.com/
- Netflix
- https://github.com/Netflix
- Downdetector
- https://downdetector.co.uk/
- Usenix
- SRE Blogs
- AppDynamics Blog
- Atlassian Blog
- Prometheus Blog
- Rundeck Blog
- Tech At Bloomberg
- VictorOps Blog
- Additional Videos of Interest
- SLO’s & Error Budgets
- ‘SLOs for Data-Intensive Services’ with Yoann Fouquet (23:47)
- https://www.youtube.com/watch?v=ZdguHXglT8M&feature=youtu.be
- ‘Latency SLOs Done Right’ with Heinrich Hartmann (27:12)
- https://www.youtube.com/watch?v=ycsc2kCaJxM&feature=youtu.be
- ‘SLOs for Data-Intensive Services’ with Yoann Fouquet (23:47)
- Monitoring & Service Level Indicators
- ‘Building a Scalable Monitoring System’ with Molly Struve (26.48)
- https://www.youtube.com/watch?v=vl1ecpFohZQ&feature=youtu.be
- ‘Building a Scalable Monitoring System’ with Molly Struve (26.48)
- SLO’s & Error Budgets
- SRE Books
- Site Reliability Engineering
- Betsy Beyer, Chris Jones, Jennifer Petoff and Niall Richard Murphy
- https://landing.google.com/sre/sre-book/toc/index.html
- Betsy Beyer, Chris Jones, Jennifer Petoff and Niall Richard Murphy
- The Site Reliability Workbook Betsy Beyer, Niall Richard
- Murphy, David K. Rensin, Kent Kawahara and Stephen Thorne
- https://landing.google.com/sre/workbook/toc/
- Murphy, David K. Rensin, Kent Kawahara and Stephen Thorne
- Facts and Fallacies of Software Engineering
- Robert L. Glass
- https://www.amazon.com/Facts-Fallacies-Software-Engineering-Robert/dp/0321117425
- Robert L. Glass
- Chaos Engineering
- Ali Basiri, Nora Jones, Aaron Blohowiak, Lorin Hochstein, Casey Rosenthal
- https://www.oreilly.com/library/view/chaos-engineering/9781491988459/
- Training Site Reliability Engineers Jennifer Petoff, JC van Winkel & Preston Yoshioka with JessieYang, Jesus Climent Collado &Myk Taylor
- https://landing.google.com/sre/resources/practicesandprocesses/training-site-reliability-engineers/
- Ali Basiri, Nora Jones, Aaron Blohowiak, Lorin Hochstein, Casey Rosenthal
- Site Reliability Engineering
- Case Stories Featured in the Course
- Accenture
- 3: Reducing Toil
- https://techbeacon.com/devops/how-accenture-retrofitted-site-reliability-engineering
- Bloomberg
- 1: SRE Principles & Practices
- https://player.fm/series/devops-chat/site-reliabilityengineering-sre-bloomberg-w-stig-sorenson
- https://www.techatbloomberg.com/blog/bloomberg-bets-big-on-sres/
- https://www.ca.com/us/modern-software-factory/content/outsmarting-outages-bloomberg-banks-on-sre-for-reliability.html
- 1: SRE Principles & Practices
- 3: Reducing Toil
- Evernote
- 2: SLO’s & Error Budgets
- https://landing.google.com/sre/workbook/chapters/slo-engineering-case-studies/
- 2: SLO’s & Error Budgets
- Home Depot
- 2: SLO’s & Error Budgets
- https://landing.google.com/sre/workbook/chapters/slo-engineering-case-studies/
- 2: SLO’s & Error Budgets
- Netflix
- 6: Antifragility and Learning from Failure
- https://github.com/Netflix/SimianArmy
- 6: Antifragility and Learning from Failure
- Sage Group
- 7: Organizational Impact of SRE
- https://www.meetup.com/DevOpsNorthEast/events/262263231/
- 7: Organizational Impact of SRE
- Standard Chartered
- 5: SRE Tools & Automation
- https://www.youtube.com/watch?v=d5IMvK0YHTg
- 5: SRE Tools & Automation
- Trivago
- 4: Monitoring & SLI’s
- https://www.google.com/url?sa=t&rct=j&q=&esrc=s&source=web&cd=11&cad=rja&uact=8&ved=2ahUKEwj4m6HJ9qXjAhU_QEEAHX6-CgQQFjAKegQIABAC&url=http%3A%2F%2Fpages.catchpoint.com%2Frs%2F005-RHC-551%2Fimages%2FCatchpoint-Case-Study-Trivago.pdf&usg=AOvVaw3UUcZ1bqtes0_99EYcBZSm
- 4: Monitoring & SLI’s
- VictorOps (Splunk)
- 8: SRE, Other Frameworks, Trends
- https://victorops.com/blog/site-reliability-engineer-sre-roles-and-responsibilities
- 8: SRE, Other Frameworks, Trends
- Accenture


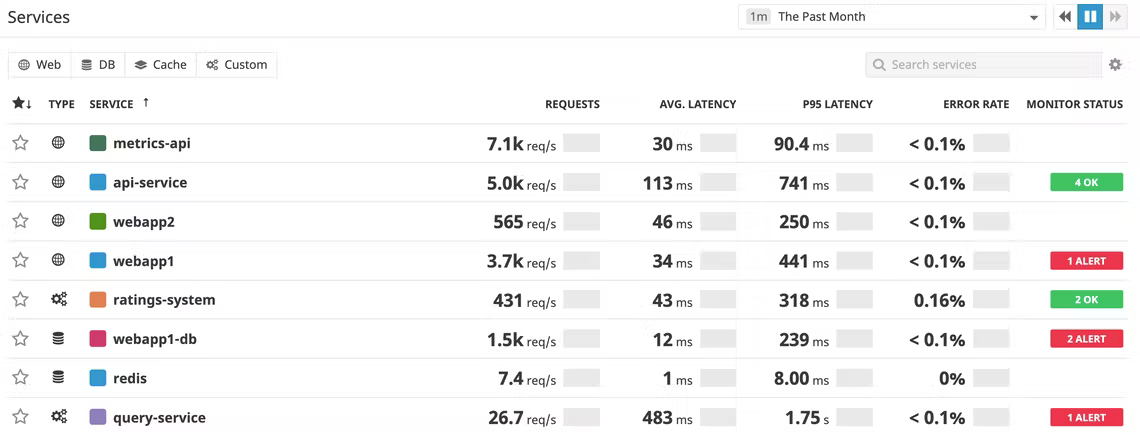
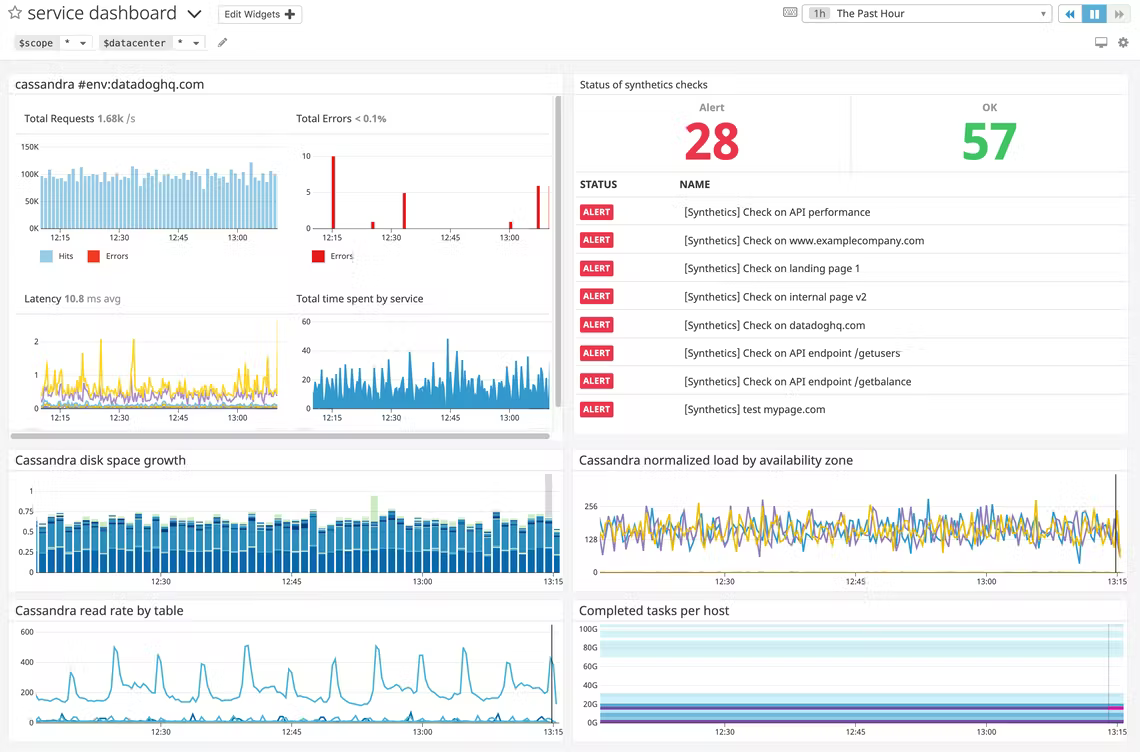

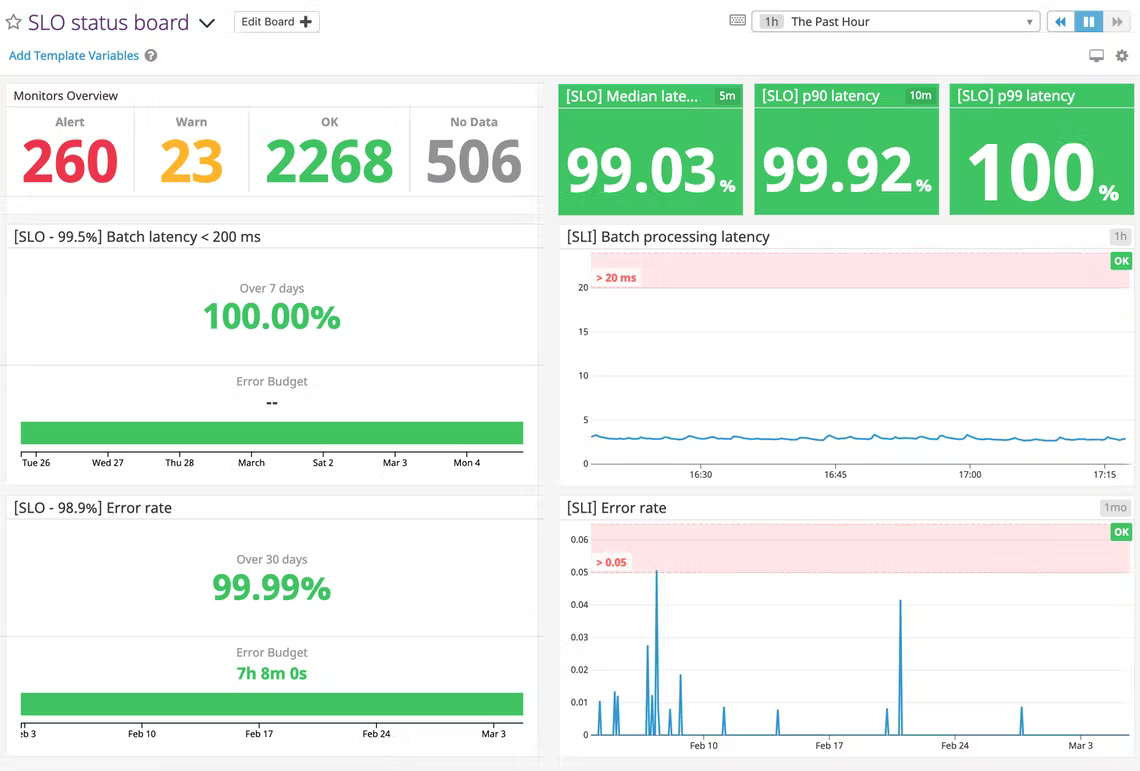
Extra
- https://medium.com/swlh/a-design-analysis-of-cloud-based-microservices-architecture-at-netflix-98836b2da45f
- https://netflixtechblog.com/making-the-netflix-api-more-resilient-a8ec62159c2d
- https://netflixtechblog.com/byte-down-making-netflixs-data-infrastructure-cost-effective-fee7b3235032
- https://netflixtechblog.com/telltale-netflix-application-monitoring-simplified-5c08bfa780ba
- https://netflixtechblog.com/introducing-aardvark-and-repokid-53b081bf3a7e
- https://netflixtechblog.com/improving-netflixs-operational-visibility-with-real-time-insight-tools-ab5e7af062e5



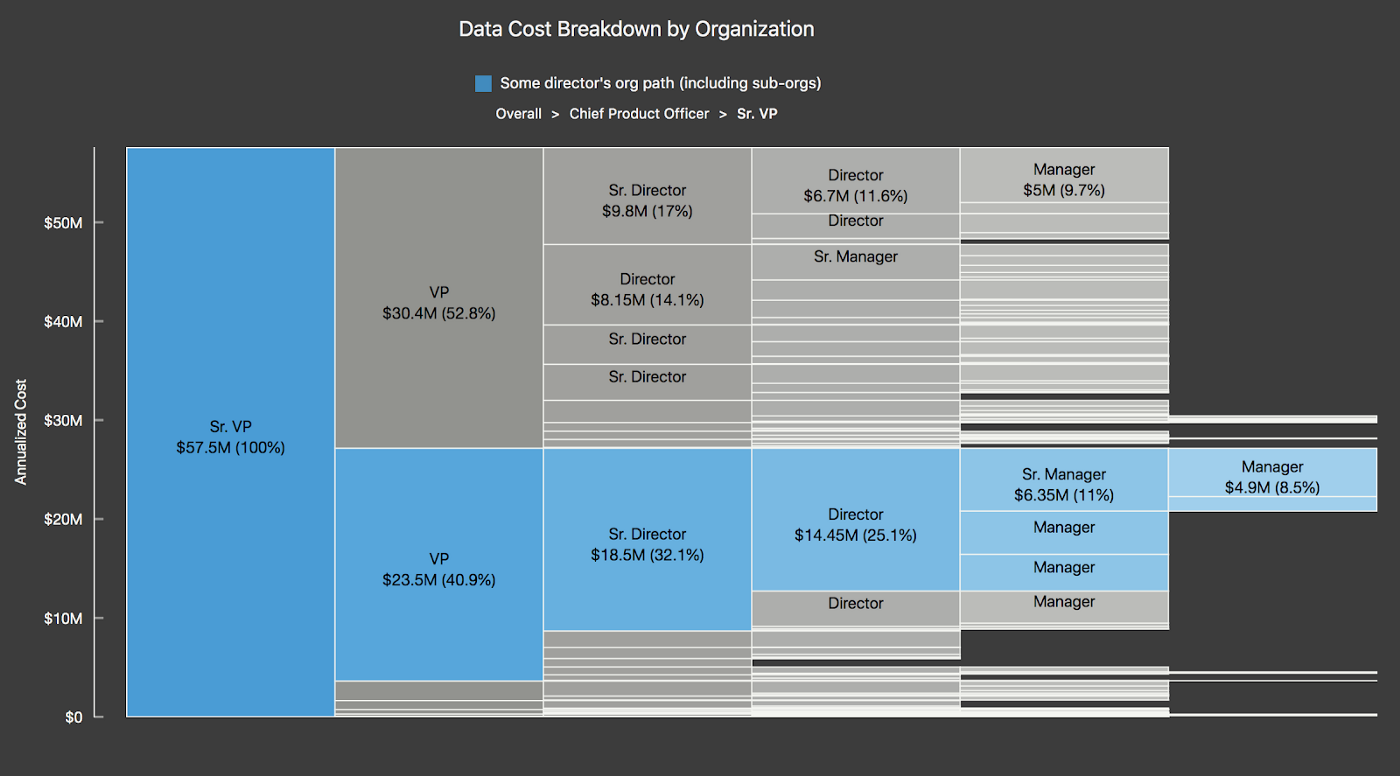

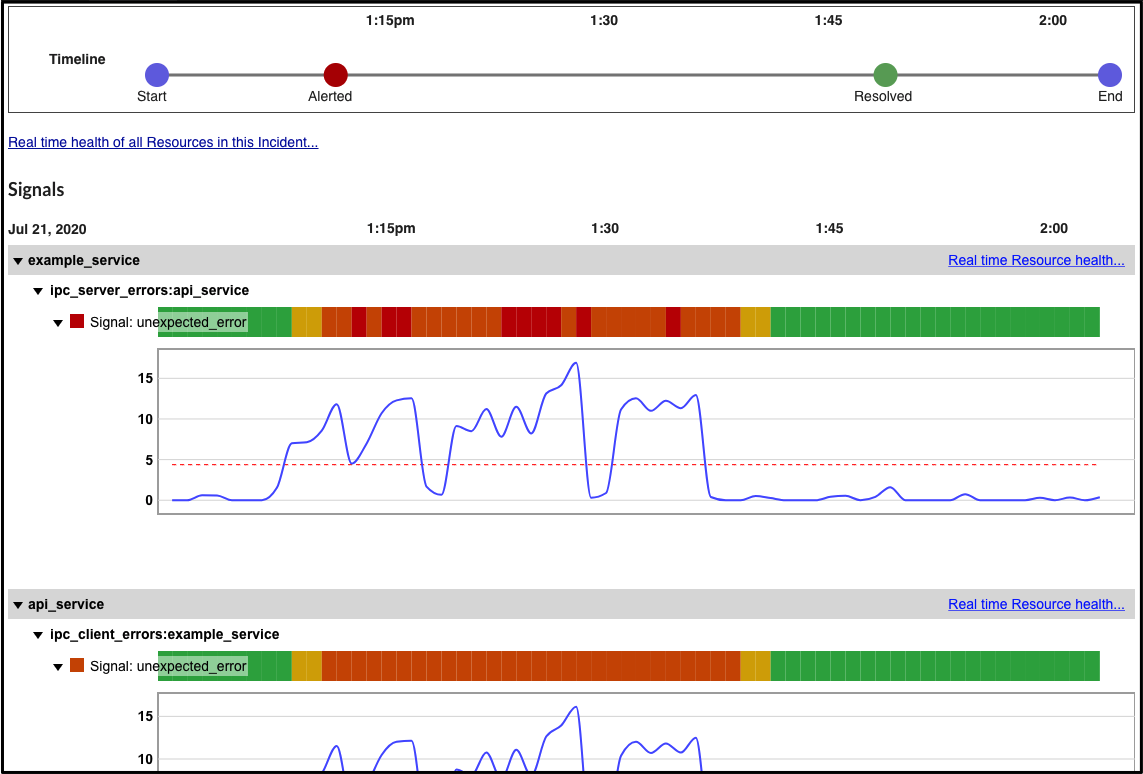

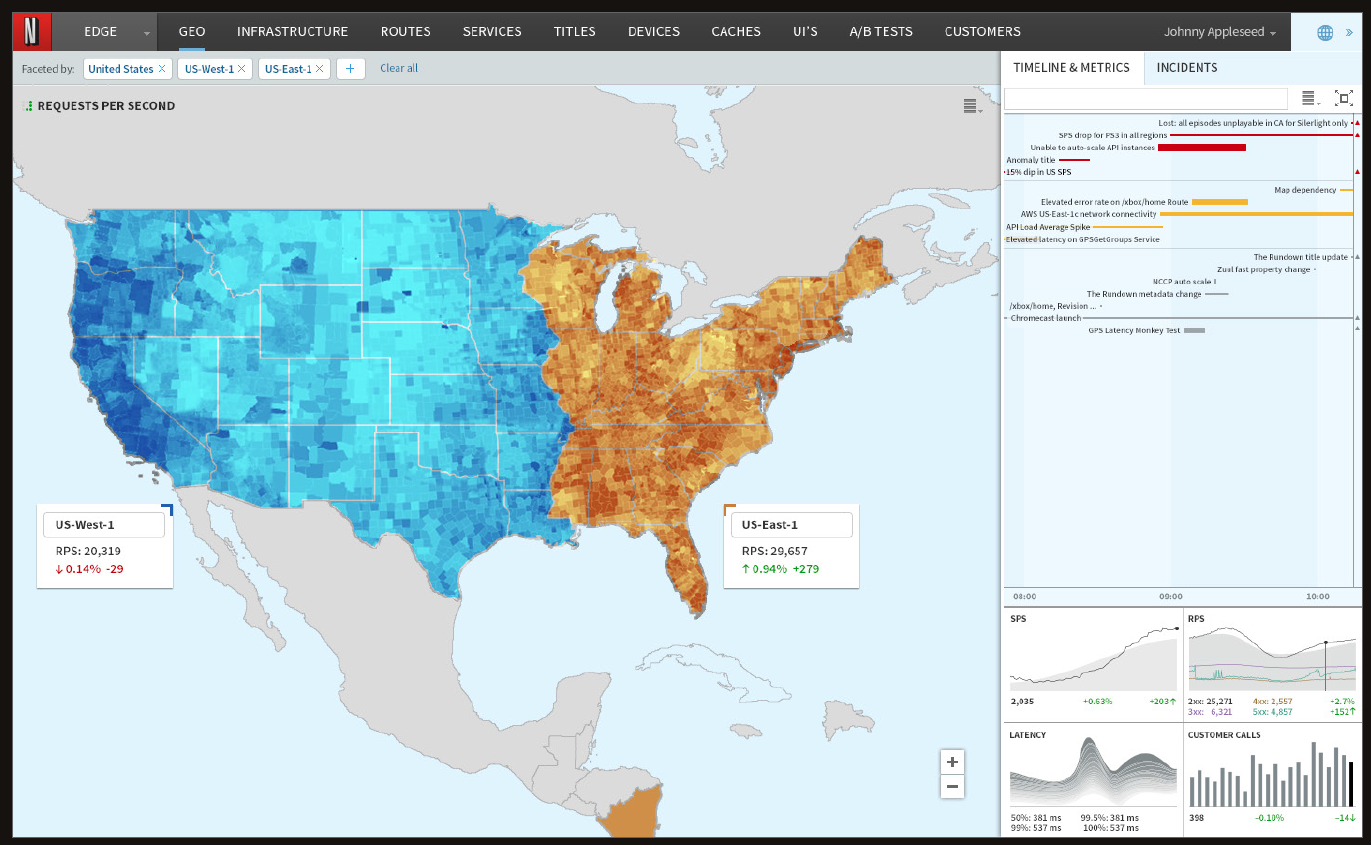

https://app.mural.co/t/quode7784/m/quode7784/1620913174271/6e3d976c582f1a5fe81dfb229210ef6a0fdf8369?sender=u5f9b4585ec6111ca5bf91065