
Compression
zfs get all <poolname>
NAME PROPERTY VALUE SOURCE
oricoB type filesystem -
oricoB creation Wed Oct 13 18:23 2021 -
oricoB used 1.06M -
oricoB available 10.4T -
oricoB referenced 170K -
oricoB compressratio 1.00x -
oricoB mounted yes -
oricoB quota none default
oricoB reservation none default
oricoB recordsize 128K default
oricoB mountpoint /mnt/oricoB default
oricoB sharenfs off default
oricoB checksum on default
oricoB compression lz4 local
oricoB atime on default
zfs set compression=lz4 <poolname>
Many disk setup
for dev in da2 da3 da4 da5 da6;
do
suffix=$(smartctl -i /dev/$dev | grep "Serial Number" | tail -c 5)
echo "$dev $suffix"
gpart destroy -F $dev
gpart create -s gpt $dev
gpart add -t freebsd-zfs -l "oricoC3-$suffix" $dev
done
Utils
https://forums.freebsd.org/threads/how-find-numeric-id-of-drive-zfs.62475/
geom disk list
camcontrol devlist
camcontrol identify da0
glabel list
zpool get all <poolname>
Wipe drives
https://www.truenas.com/community/threads/cant-wipe-drive-operation-not-permitted.83470/
sysctl kern.geom.debugflags=0x10
dd if=/dev/zero of=/dev/ada2 bs=1m count=1
dd if=/dev/zero of=/dev/ada2 bs=1m oseek=`diskinfo ada2 | awk '{print int($3 / (1024*1024)) - 4;}'`
Partitions
https://forums.freebsd.org/threads/labeling-partitions-done-right-on-modern-computers.69250/
gpart destroy -F da6
gpart create -s gpt da6
gpart add -t freebsd-zfs -l oricoA-labelX da6
# or
gpart create -s gpt da7
gpart add -t freebsd-zfs da7
gpart modify -i1 -l oricoA-labelY da7
zpool create -f <poolname> raidz1 /dev/gpt/oricoA-*
zfs set compression=lz4 <poolname>
RAID6 & RAID 10
zpool create -f data6 raidz2 sda sdb sdc sdd
zpool create -f data10 mirror sda sdb mirror sdc sdd
Replace
zpool offline <pool> sdl
zpool replace <pool> sdl sdm
Export
zpool export data10
zpool import
zpool import <pool-name/pool-id>
# import a destroyed pool
zpool destroy data6
zpool import -D data6
Add spare
https://forums.freebsd.org/threads/adding-new-drive-as-a-spare-to-zpool.68196/
zpool add (pool) spare (disk)
Snapshot & Clone
zfs snapshot <pool>/<fs>@snap1
zfs clone <pool>/<fs>@snap1 <pool>/<fs2>
Backups
https://docs.oracle.com/cd/E18752_01/html/819-5461/gbchx.html#gbscu
zfs send pool/fs@snap | gzip > backupfile.gz
incremental
https://docs.oracle.com/cd/E19253-01/819-5461/gbinw/index.html
zfs send -i tank/dana@snap1 tank/dana@snap2 | ssh host2 zfs recv newtank/dana
between hosts
https://www.reddit.com/r/zfs/comments/axnnj2/zfs_send_into_gunzip_file_on_ssh_host/
zfs send -c snapshot |ssh -x user@remotehost "cat > snapshot.zfs"
zfs send filesystem@snapshot | gzip -cf | ssh host 'gunzip | zfs recv ...'
Send & Recv
https://docs.oracle.com/cd/E18752_01/html/819-5461/gbchx.html
zfs send <pool>/<fs>@<snap> | zfs recv <pool2>/<fs>
https://oshogbo.vexillium.org/blog/66/ zfs recv not to throw away data in case of an interruption -s flag.
# sender end
zfs get -H -o value receive_resume_token <pool>/<vol>
<token>
zfs send -t <token>
# receiver end
zfs recv -s <pool>/<fs>
Send
# zfs send tank/data@snap1 | zfs recv spool/ds01
host1# zfs send tank/dana@snap1 | ssh host2 zfs recv newtank/dana
host1# zfs send -i tank/dana@snap1 tank/dana@snap2 | ssh host2 zfs recv newtank/dana
host1# zfs send -i snap1 tank/dana@snap2 > ssh host2 zfs recv newtank/dana
# zfs send pool/fs@snap | gzip > backupfile.gz
Receive
# zfs send tank/gozer@0830 > /bkups/gozer.083006
# zfs receive tank/gozer2@today < /bkups/gozer.083006
# zfs rename tank/gozer tank/gozer.old
# zfs rename tank/gozer2 tank/gozer
replace tank
zpool status zpool offline tank gpt/5TB-N5W1 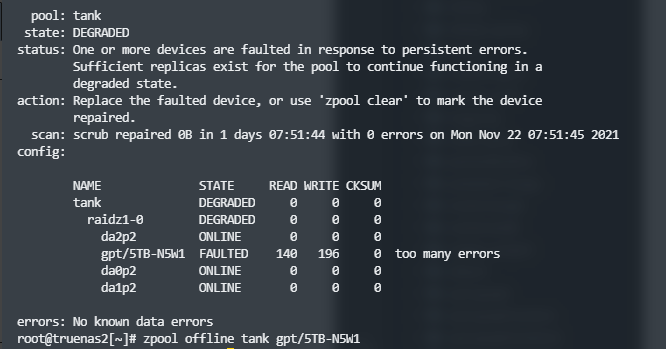
zpool status 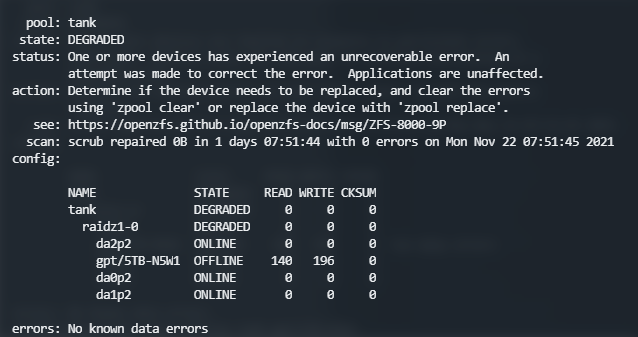
zpool replace tank gpt/5TB-N5W1 gpt/5TB-0VZJ 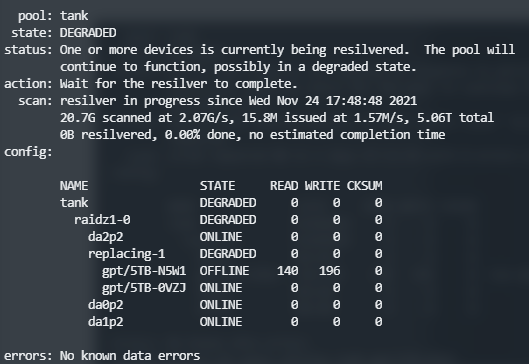
possible to split stream created by “zfs send”
https://www.reddit.com/r/zfs/comments/oeq17q/is_it_possible_to_split_stream_created_by_zfs/h48admy/
zfs send <...> | mbuffer -A "echo Next Drive; read a < /dev/tty;" -D 2000G -o /dev/sdx
zfs send pool/dataset@snapshot | tail -c +0 | head --bytes 1000000000 > /disk1/chunk.1
zfs send pool/dataset@snapshot | tail -c +1000000000 | head --bytes 1000000000 > /disk2/chunk.2
zfs send pool/dataset@snapshot | tail -c +2000000000 | head --bytes 1000000000 > /disk3/chunk.3
zfs send pool/dataset@snapshot | tail -c +3000000000 | head --bytes 1000000000 > /disk4/chunk.4
If you can’t connect all the disks simultaneously at the receiving end either, you can reassemble the chunks using named pipes.
Create a fifo for each chunk:
mkfifo pipe{1,2,3}
Start receiving those chunks with ZFS. This’ll hang waiting for data to start arriving:
cat pipe1 pipe2 pipe3 | zfs recv destpool/dest
Then, in a second shell, you can attach each disk in sequence and cat their chunk into their corresponding pipe:
cat /disk1/chunk.1 > pipe1
cat /disk2/chunk.2 > pipe2
cat /disk3/chunk.3 > pipe3
ZFS will start processing data as soon as you start filling the first pipe, and the operation completes once the last pipe is read.