
Exam preparation
https://aws.amazon.com/certification/certified-solutions-architect-professional/?ch=tile&tile=getstarted
https://www.aws.training/Certification
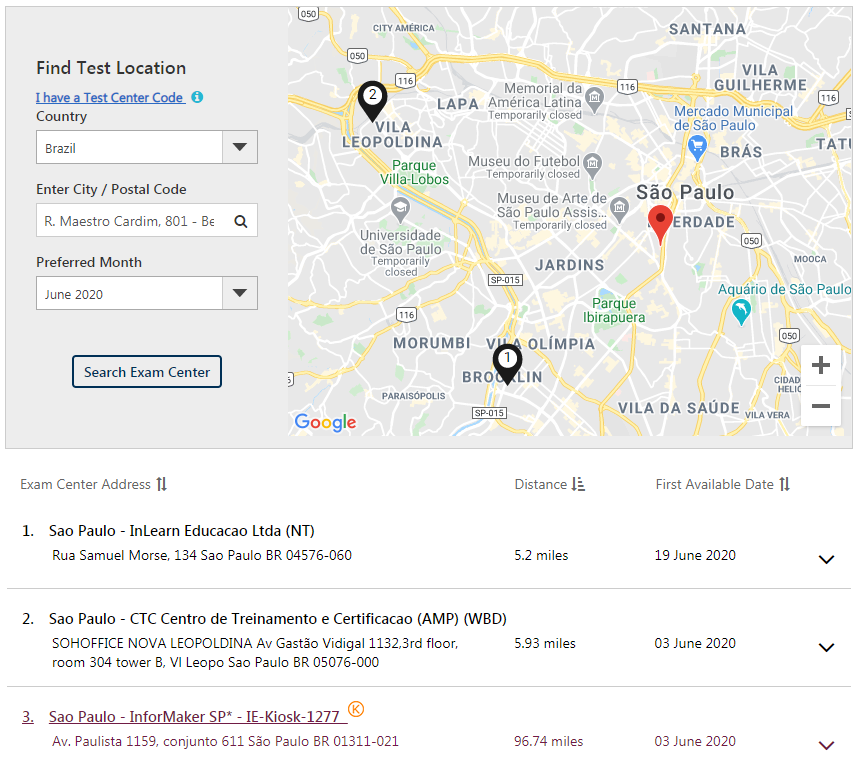
- CTC Centro de Treinamento e Certificacao (AMP) (WBD)
- (11) 2338-3292 (presencial)
InLearn Educacao Ltda (NT)(fechou)- (11) 4064-0200 (a partir dia 15/06)
- Green Tecnologia (WBD)
- (11) 3253-5299
- InforMaker SP* - IE-Kiosk-1277 <- Paulista
- Tel.: +55 11 3020-6339 3555-1585
https://aws.amazon.com/certification/certified-data-engineer-associate/
https://www.linkedin.com/posts/kennedymota_aws-awsdataengineer-awscertification-activity-7143238561134272512-GzdI?utm_source=share&utm_medium=member_desktop

Prova realizada, e digo uma coisa, estudem Amazon Redshift e ingestão de dados via Kinesis. 🤔
Resumo da prova (do que eu lembro):
-
Muito Redshift, não só conceitos básicos mas também comandos de tabelas como o VACUMM.
-
Muito Kinesis Datastream, diversos cenários de ingestão de dados, muita questão com pegadinhas do “near-realtime” adicionando um Apache Flynk nas respostas. Então é importante entender as diferenças entre eles.
-
Amazon S3, caiu duas ou três questões sobre classe de armazenamento. No demais é casos junto com o Kinesis DataFirehose, Glue, Athena e Redshift Spectrum.
-
Falando de Apache Flynk as perguntas eram bem diretas quando envolvia cenários REAL TIME.
-
Não deixou de cair uma ou outra questão sobre REDES, uma delas foi sobre um um Glue (acredito eu) recebendo erro ao tentar se comunicar com o S3 devido a falta de configuração na tabela de rotas. E outra foi uma configuração de grupo de segurança entre uma Lambda e um RDS, onde pedia para que somente a Lambda pudesse se comunicar com o RDS (clássica).
-
Muitas questões sobre como gerenciar os acessos a dados em nível de LINHA ou COLUNA, pergunta do tipo: “O departamento X só pode consultar registros onde o valor da COLUNA aws_region seja igual a Y”. Isso se misturava muito com o AWS Lake Formation e outros serviços.
-
Algumas questões também sobre como migrar os dados de um OnPrimeses para a AWS, impactando o mínimo possível ou da forma mais barata.
-
Quase todas as questões tinham duas ou três respostas certas e você vai precisar saber qual é a MAIS BARATA, com MENOR ESFORÇO OPERACIONAL, COM MENOR LATÊNCIA, etc.
-
Lembro de muitos cenários envolvendo Pipeline de Dados, mais ou menos isso: “Como você pode criar um fluxo ETL para analisar dados PII da maneira mais BARATA e com MENOR ESFORÇO OPERACIONAL?” e as respostas giravam em torno de StepFunctions e Glue Workflows.
-
Caiu assuntos de PII mas nenhuma resposta tinha o AWS Macie. As respostas eram em torno do Redshift com UDFs.
-
Entender bem quando tenho que converter para um PARQUET ou um JSON, algumas questões jogavam desta forma, você recebe um CSV ou um XML e precisa disponibilizar para o Athena para que as Querys sejam mais EFICIENTES.
Do que eu lembro é isso da maioria das perguntas. Se eu fosse separar em % de serviços/assuntos, seria algo assim:
40% Redshift (ingestão e transformação) 20% Glue 20% S3 10% EMR 10% Outros
Espero que ajude quem for fazer o beta ou até a próxima prova oficial. Vamos aguardar os resultados em 90 dias 😖