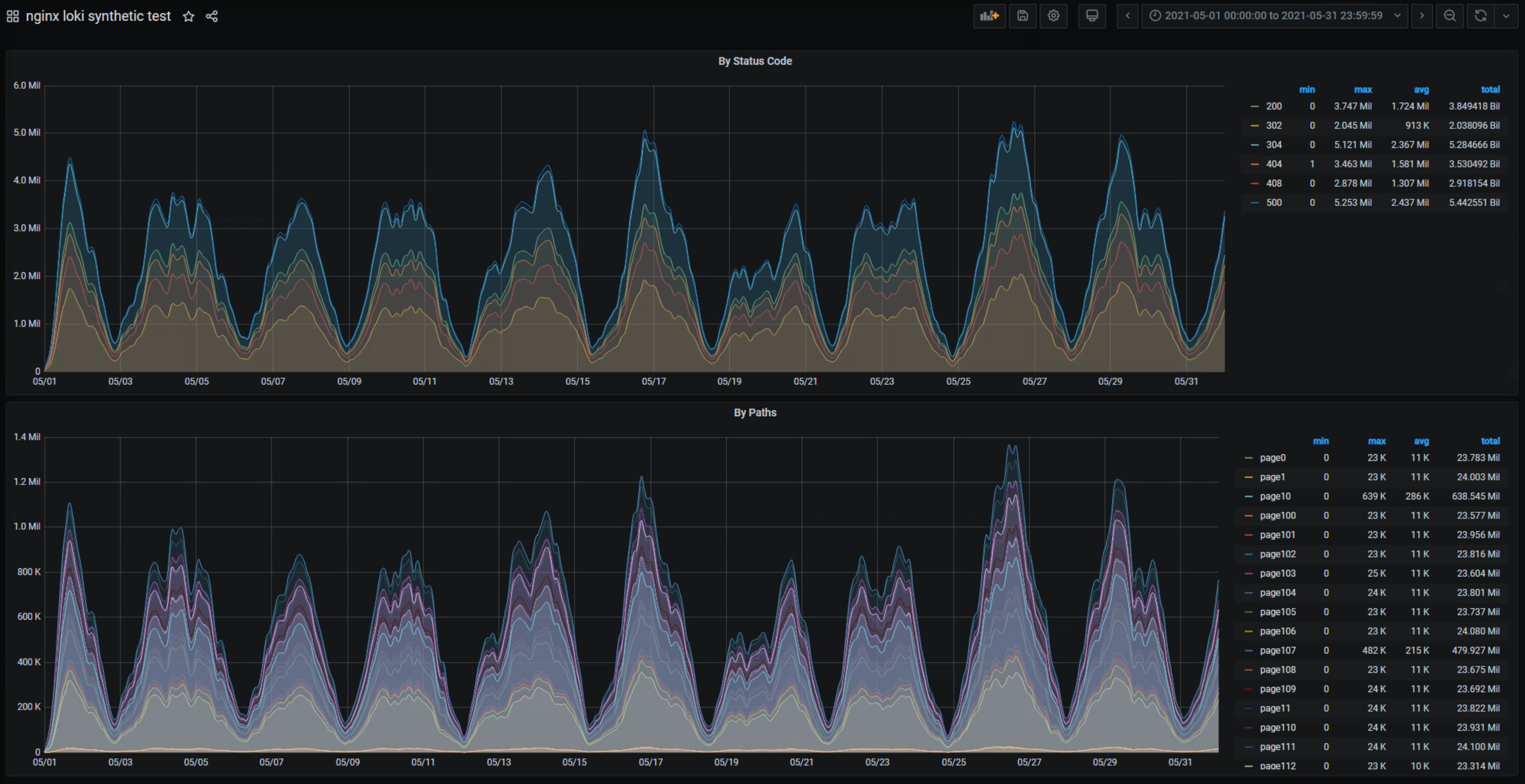
Summary
| | ELK | Splunk | Loki |
| ------------------------------- | ---------- | ------------- | ------- |
| Ingestion time elapsed | ~ 10hours | ~ 2h20minutes | ~6hours |
| Consumed indexed disk size | ~ 107Gb | ~ 40Gb | ~9Gb |
| Query 1 month (12/12h interval) | 4mins | 1h30min | 27mins |
| Query 1 month (30s interval) | ![][cross] | ![][cross] | 27mins |
| Query 1 day (12/12interval) | few secs | 4mins | 1min |
| Query 1 day (30s interval) | ![][cross] | ![][cross] | 1min |

[cross]: https://cdn3.iconfinder.com/data/icons/fatcow/16/cross.png
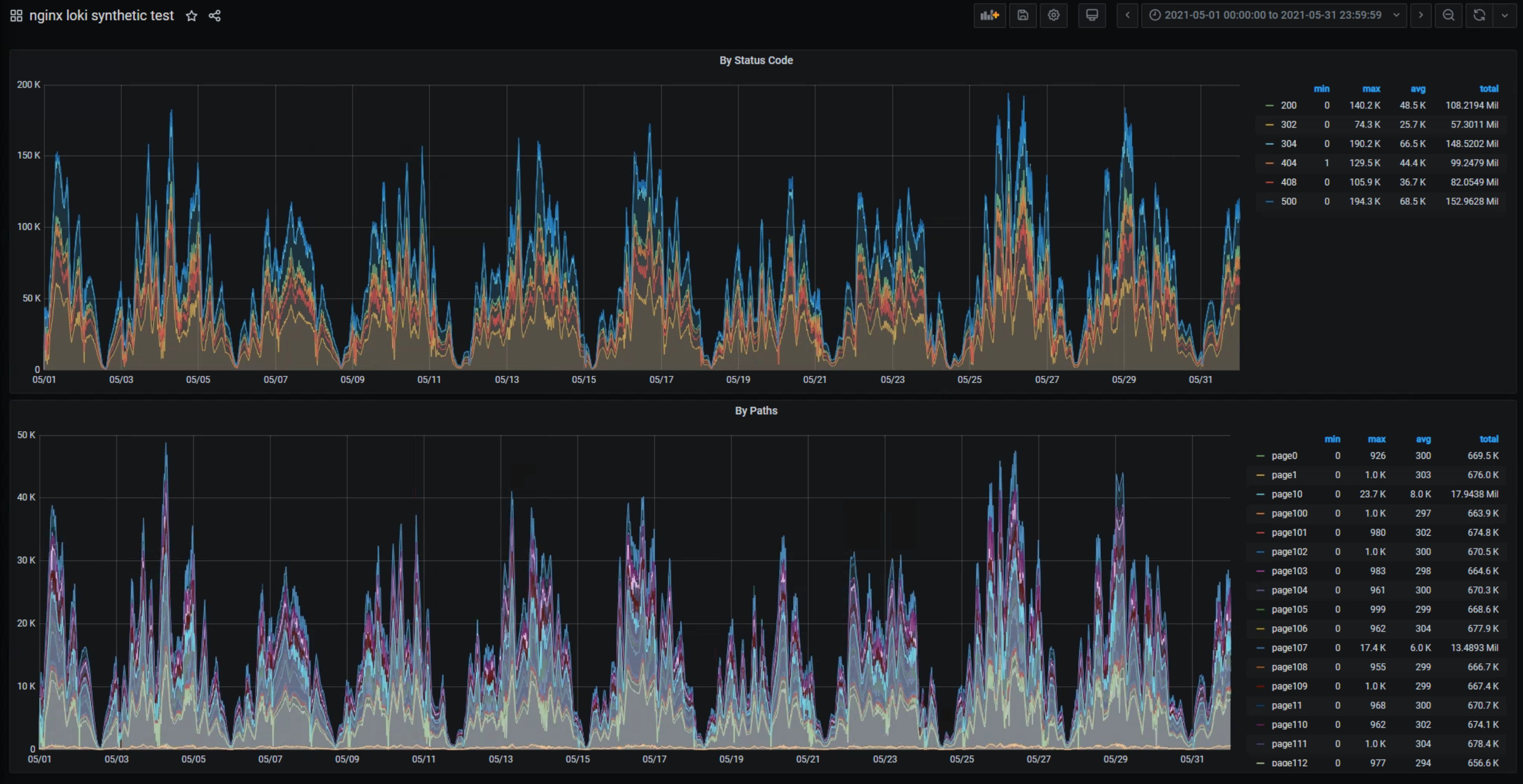
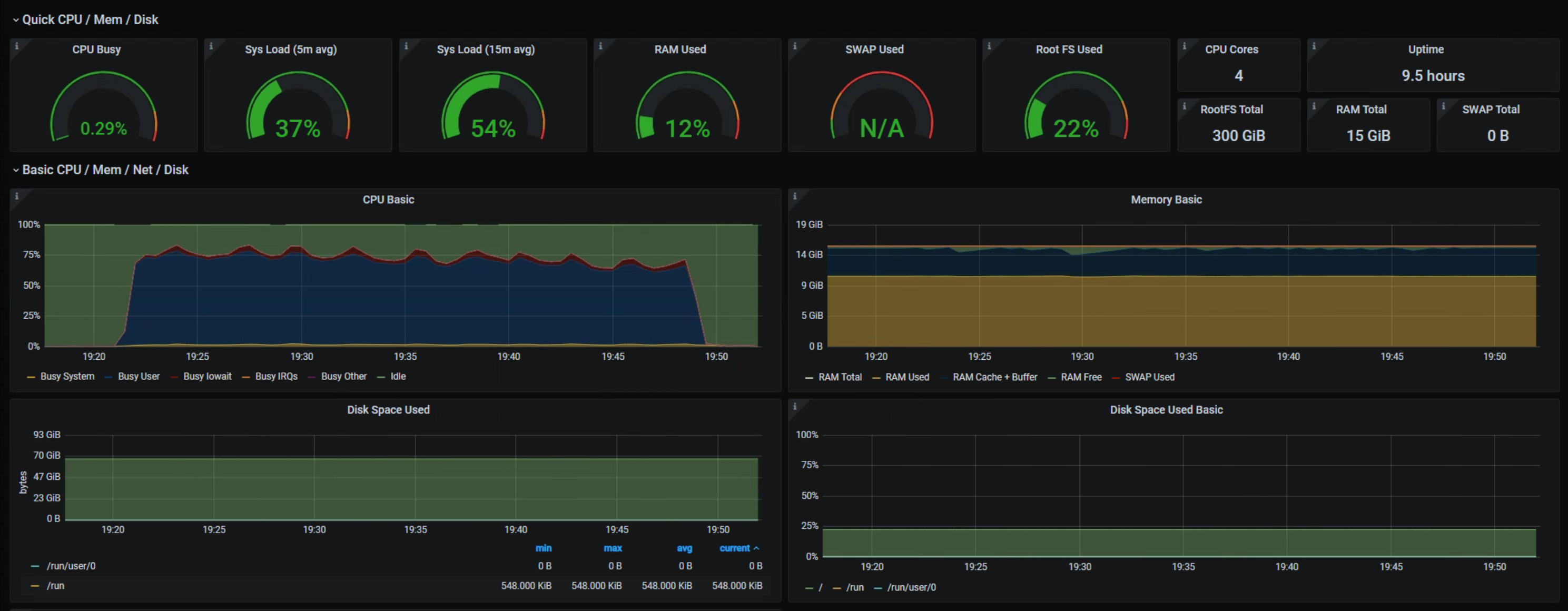
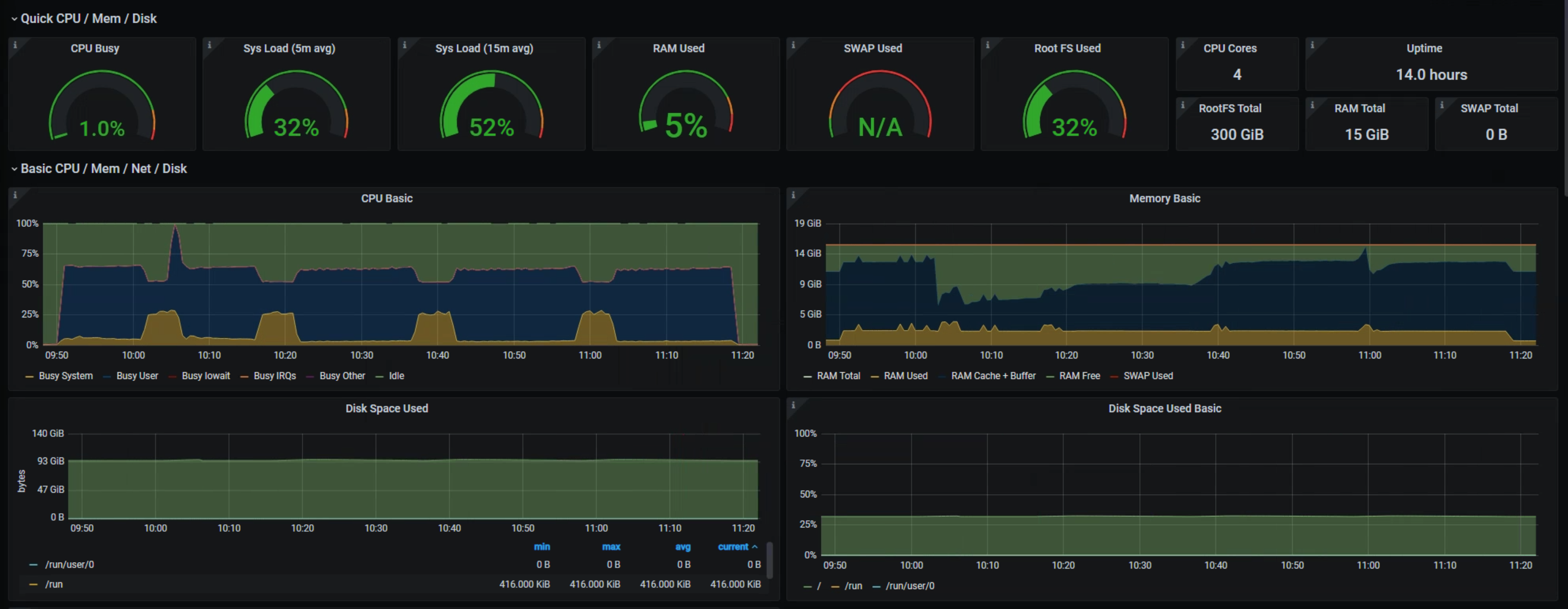
## Loki
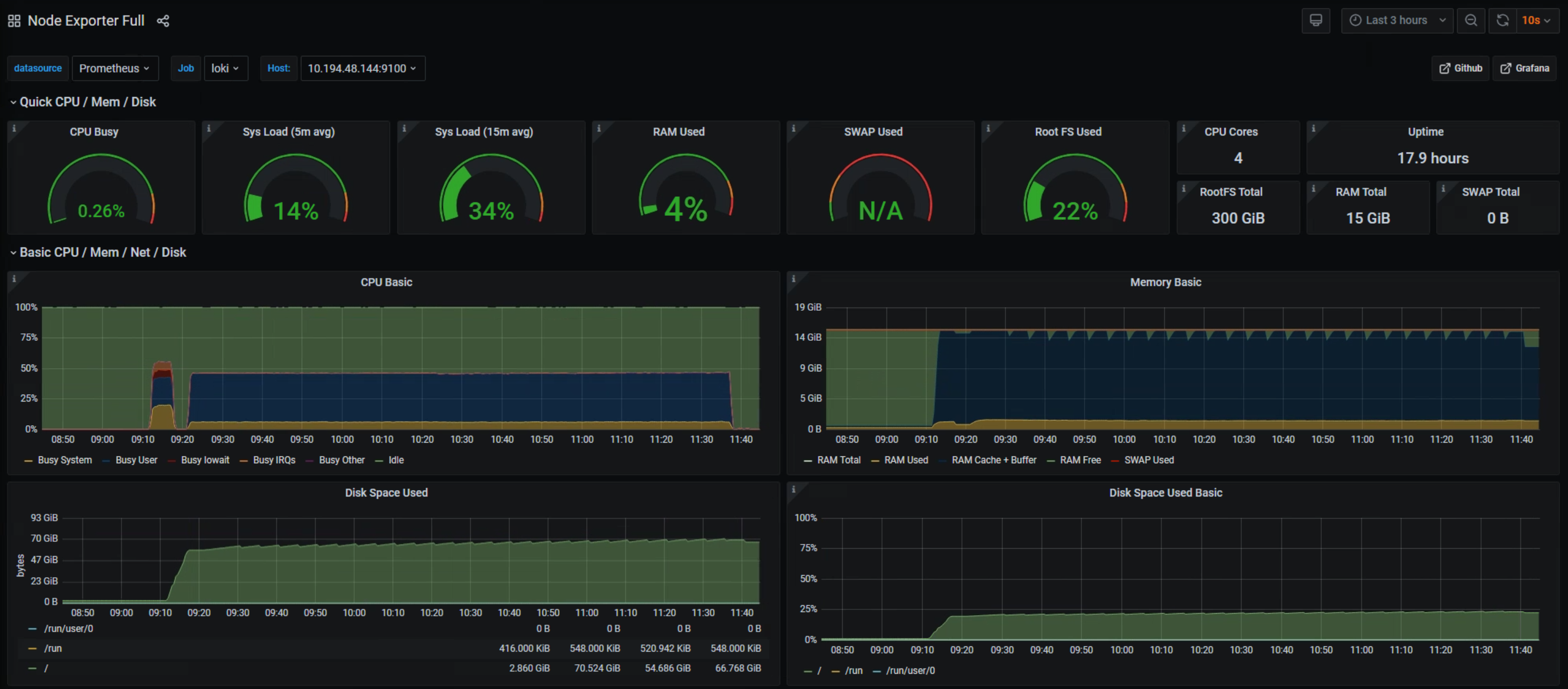
start 57gb
end 66gb
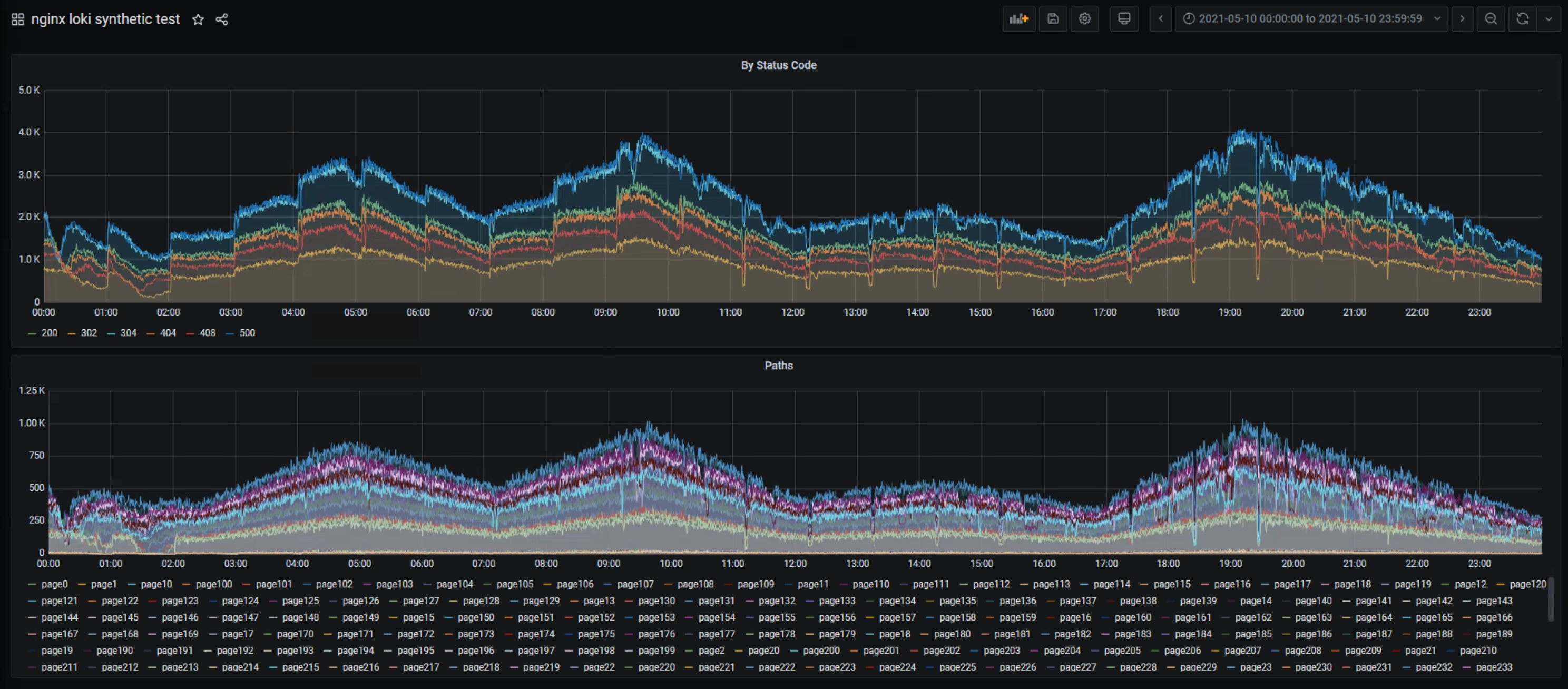
interval 30s
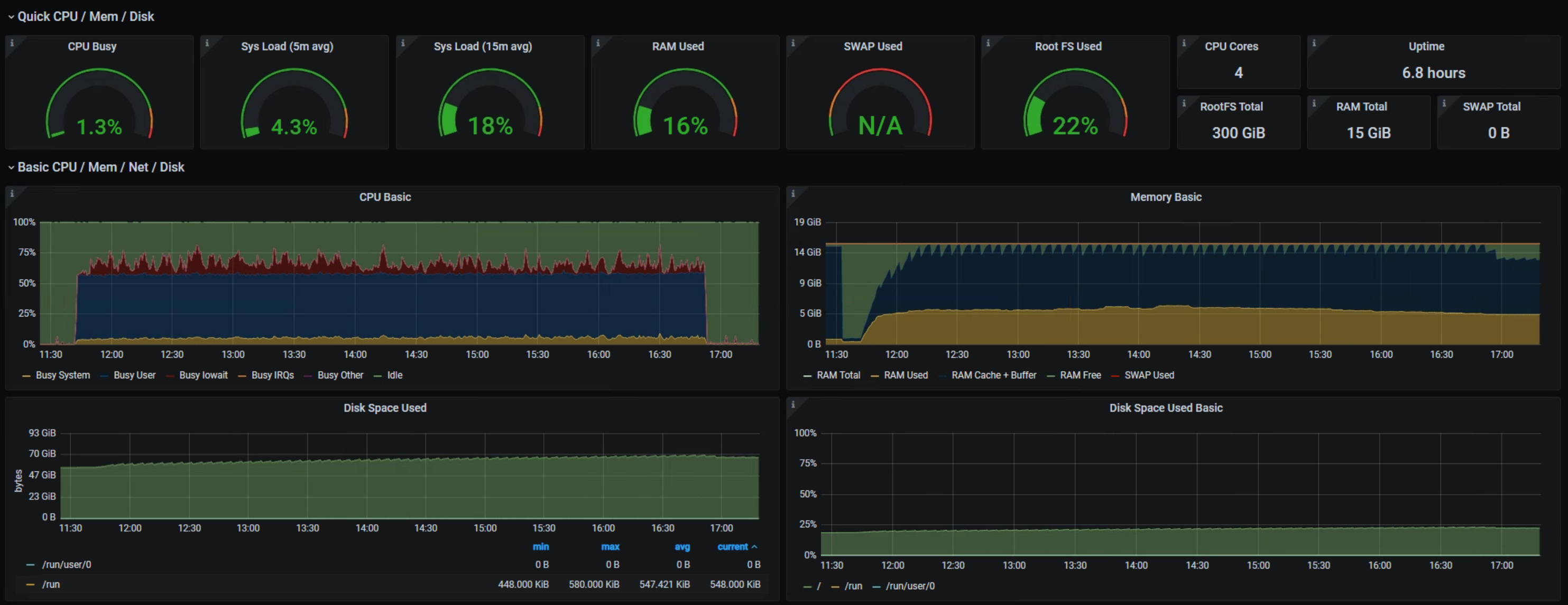
~6hours
---
12h interval
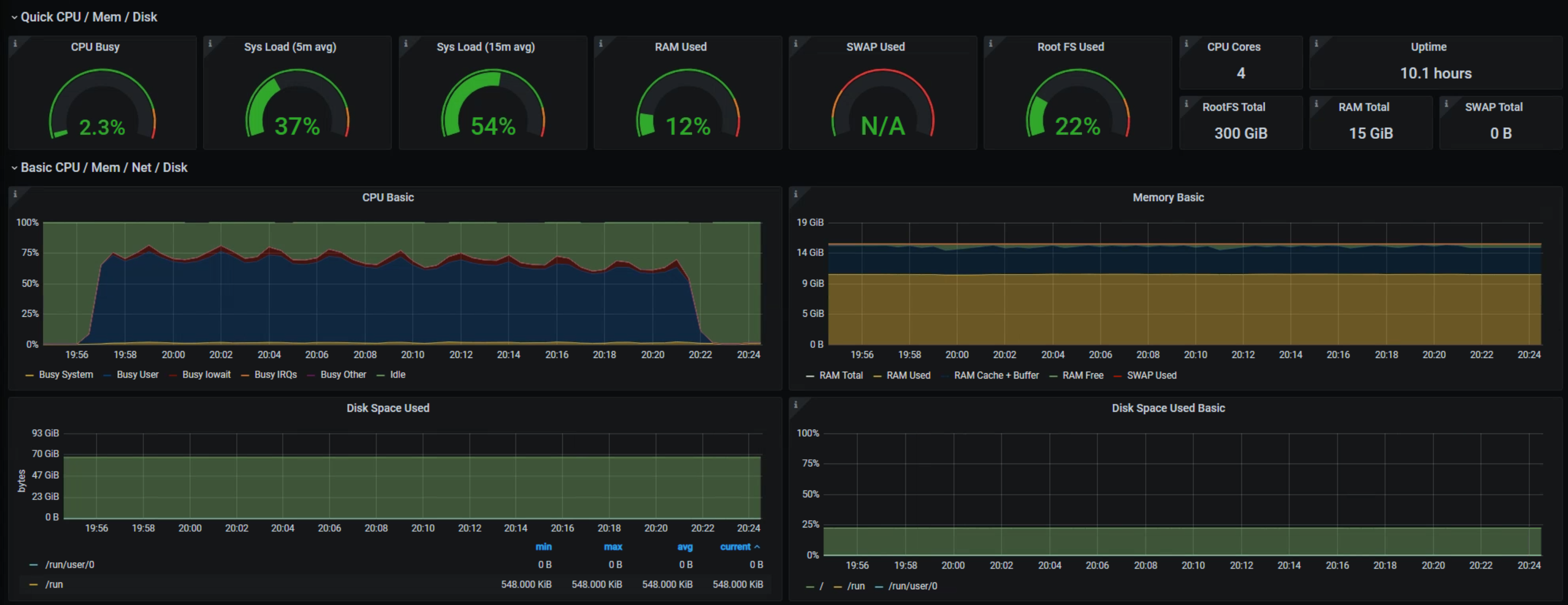
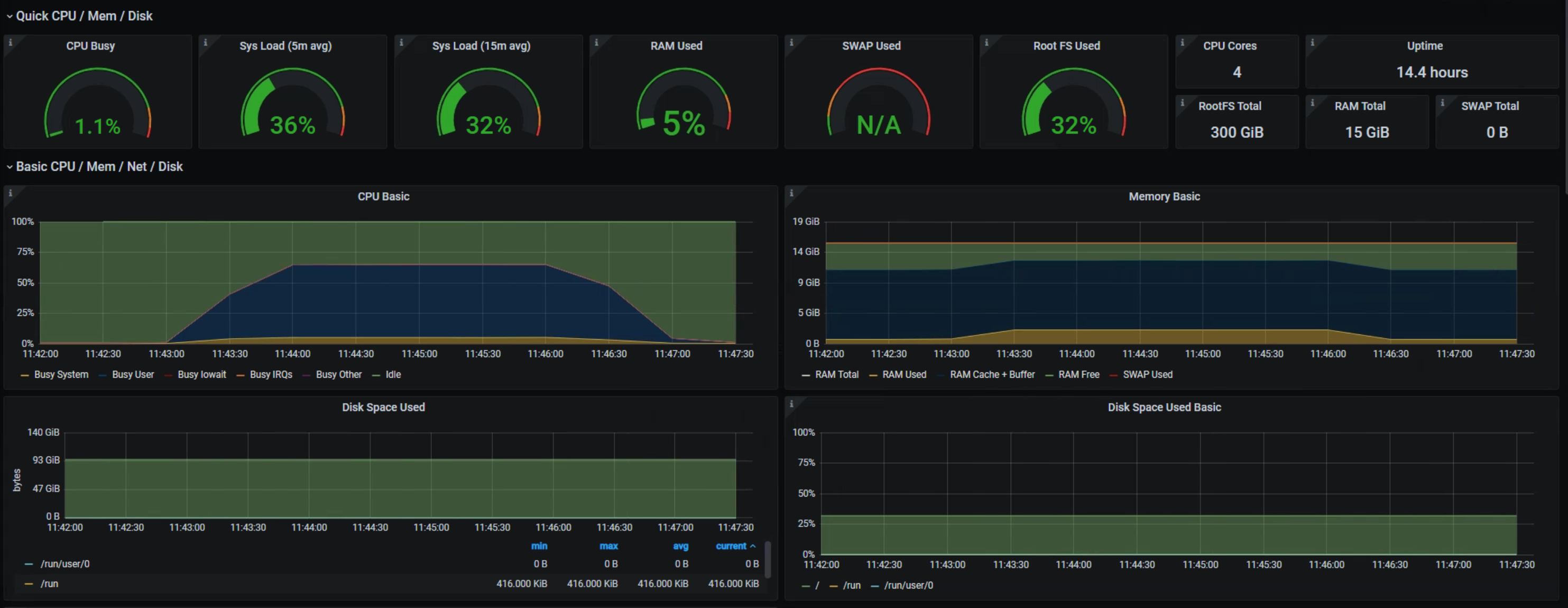
## SPLUNK
start 61gb
end 100gb
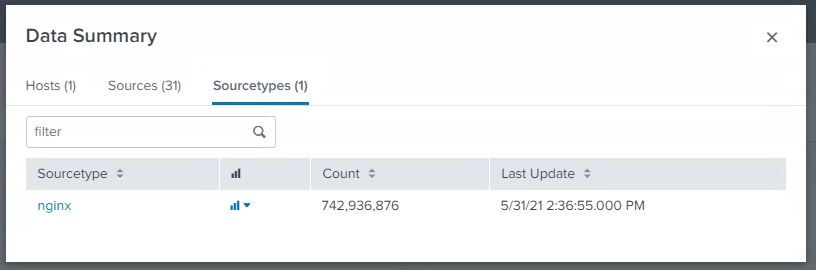
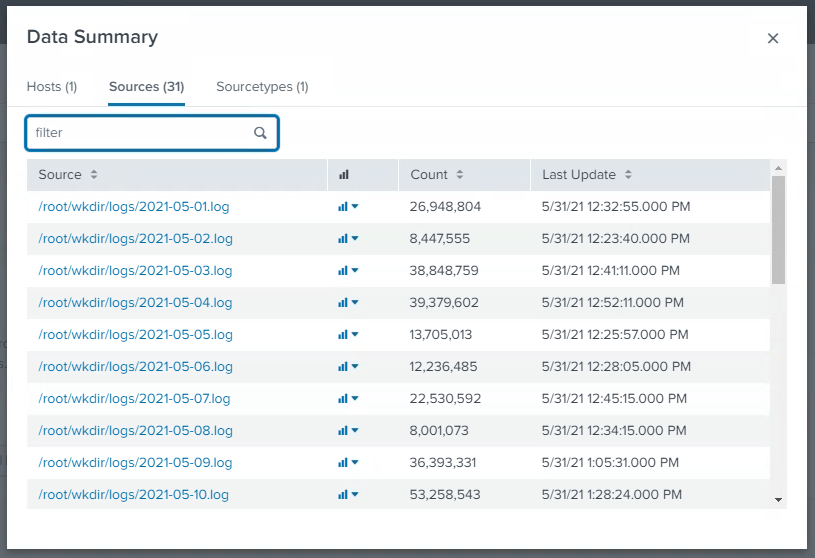
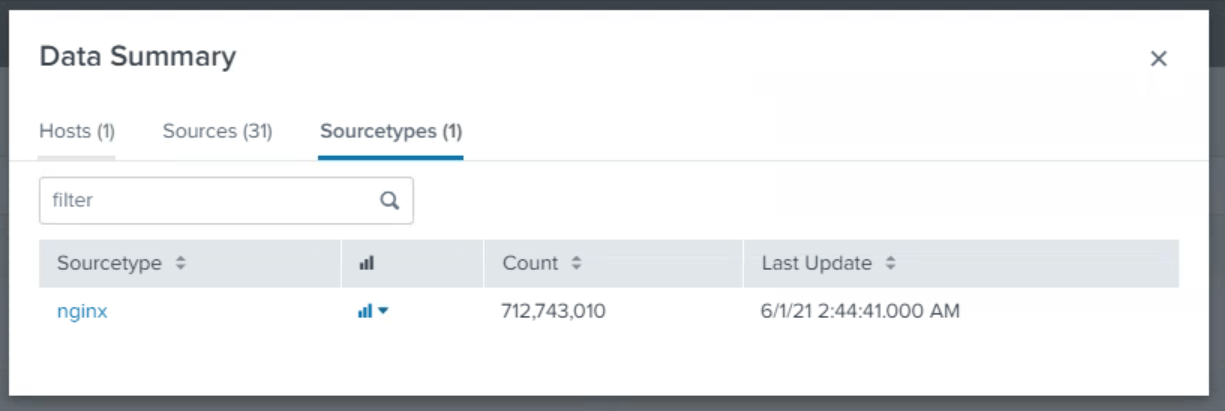
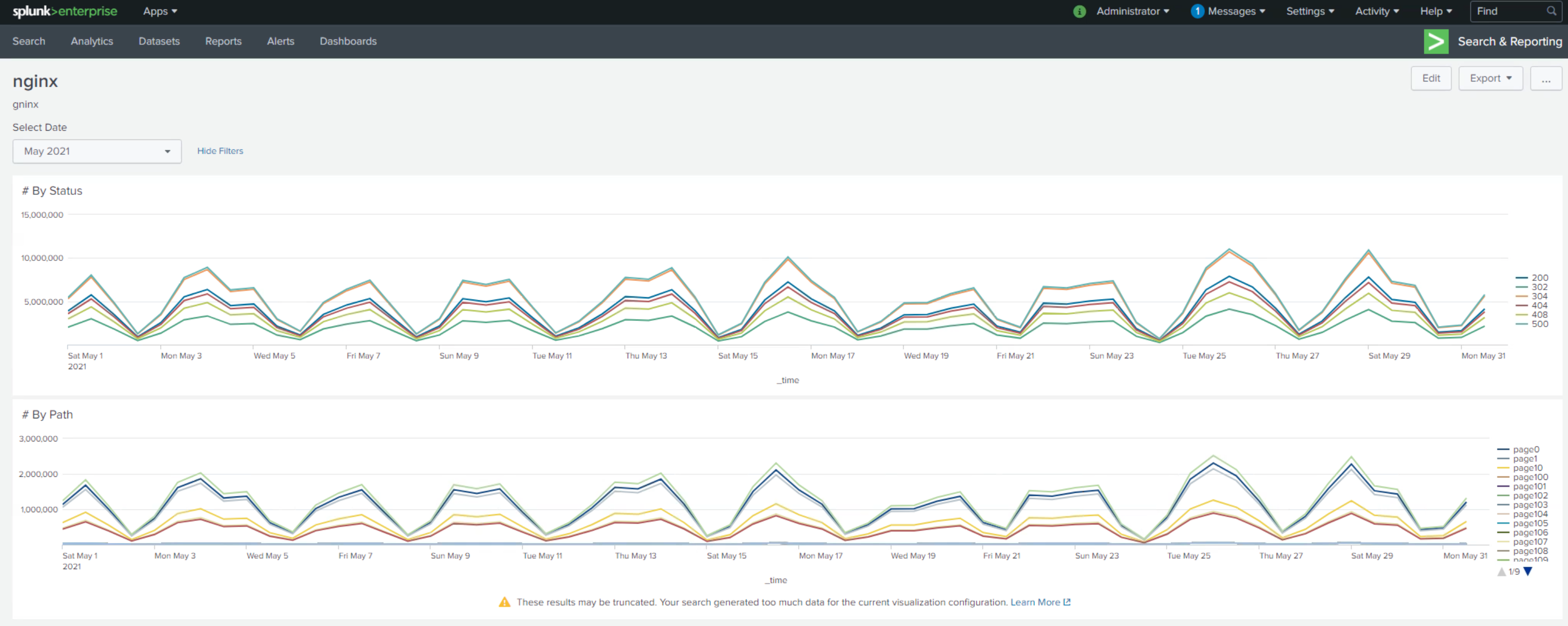
may 10th
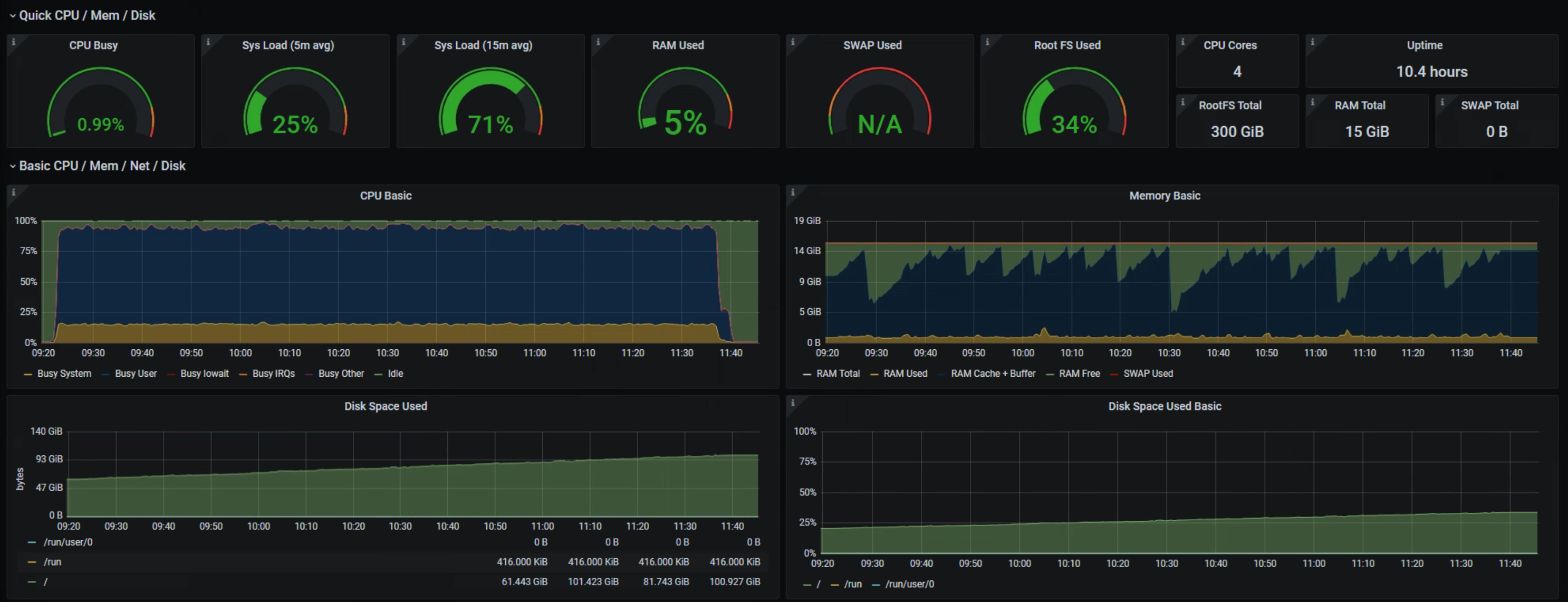
## ELK
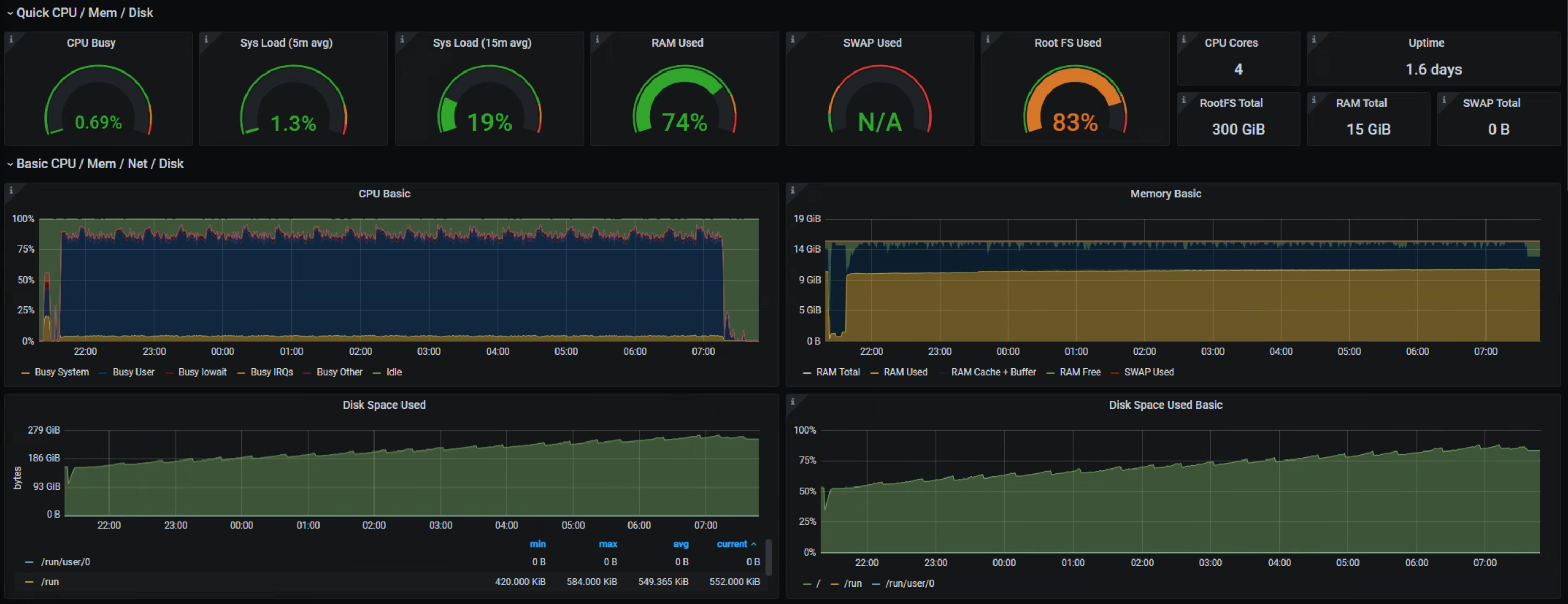
154gb 250gb
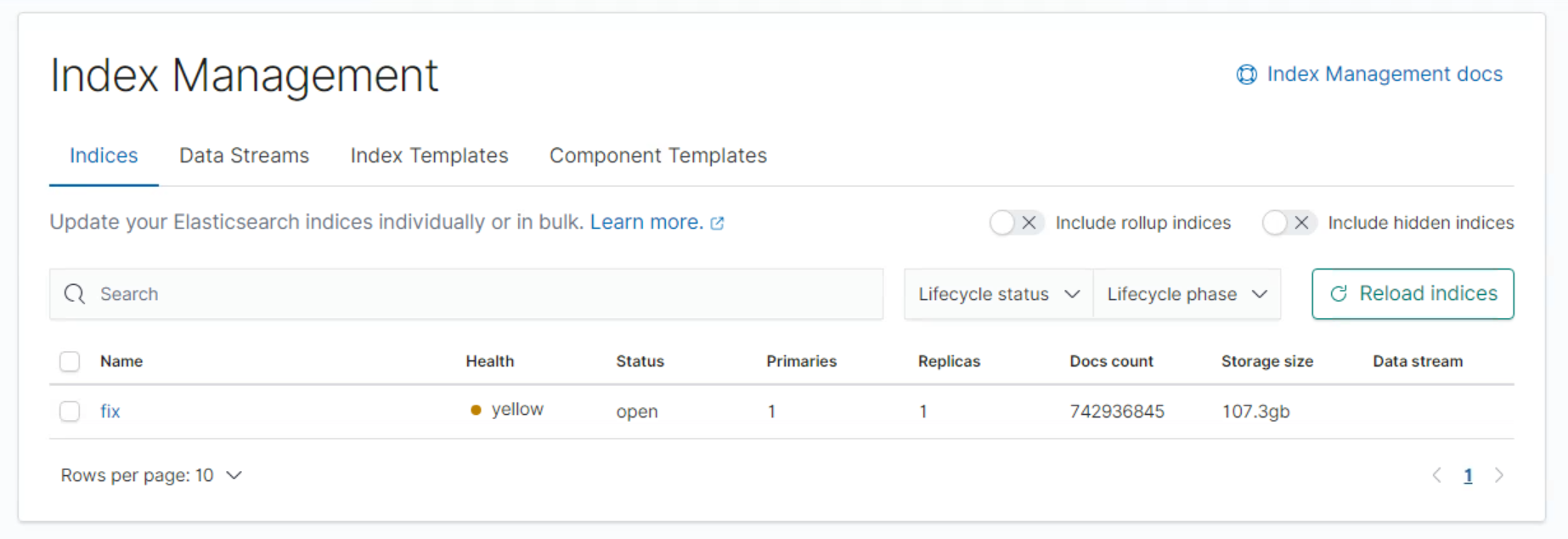
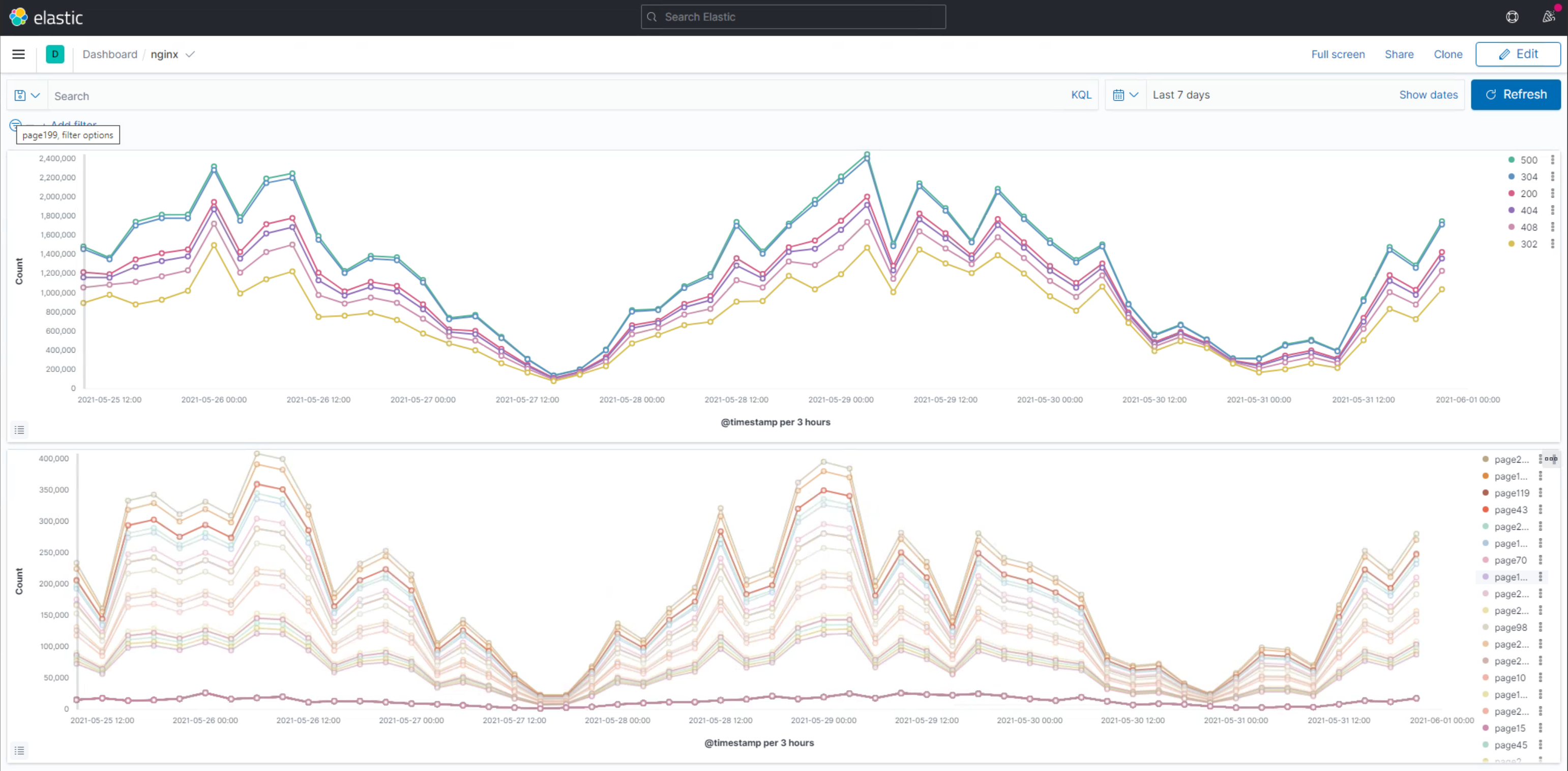
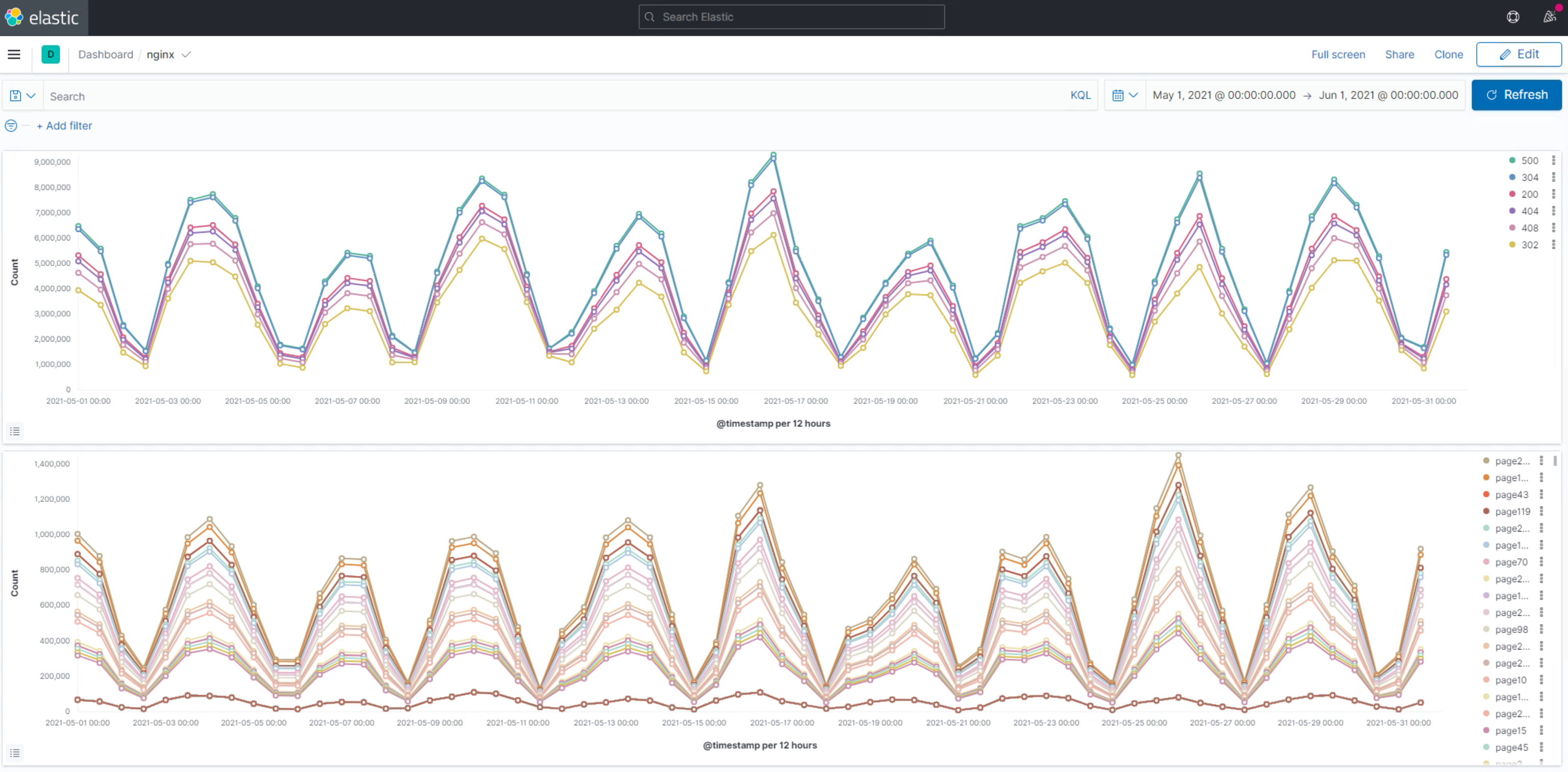
12h/12h interval
4mins
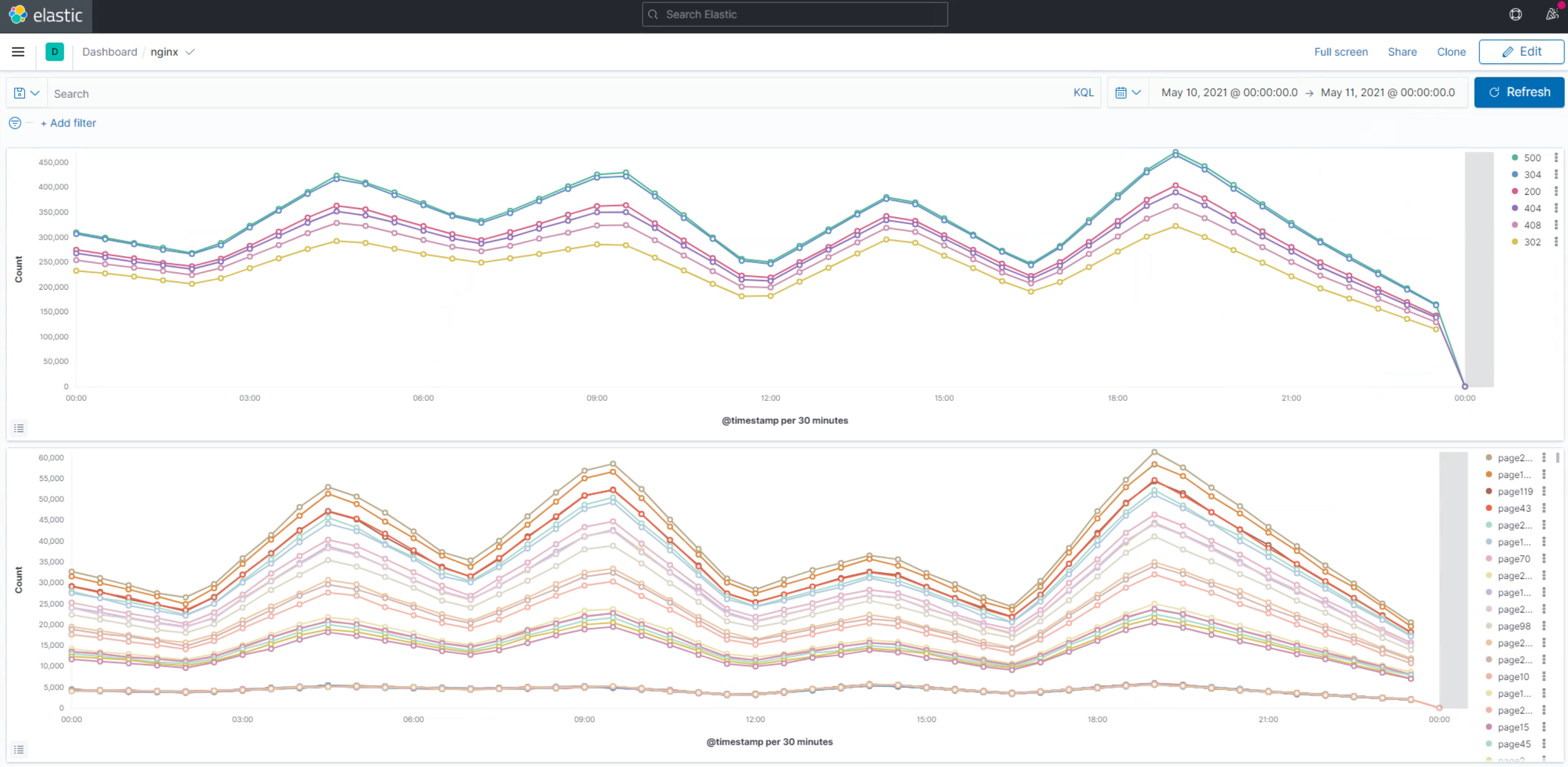
may10th
# From CMD
row.append(f"{{ \"time\":\"{datefmt}\", \"path\":\"{path}\", \"status\":\"{status_code}\" }}")
# Code
```
import pandas as pd
import math
import os
import random
import datetime
import numpy as np
import matplotlib.pyplot as plt
random.seed(8)
status_codes = [200, 304, 500, 408, 404, 302]
status_codes += [s for s in status_codes for i in range(random.randint(10,50))]
# dummy_weight
paths = [f"page{i}" for i in range(0, 300)]
paths += [p for p in random.sample(paths, 20) for i in range(random.randint(10,50))]
series = []
variance = 0
start = datetime.datetime(2021,5,1)
for i in range(310):
variance += (random.random() - 0.5)/10
val = math.cos(i/10) + variance
series.append(abs(val) * random.randint(8,40)*1000)
df = pd.DataFrame({"x": [start+datetime.timedelta(minutes=1*i) for i in range(len(series))], "y": series})
df.set_index('x').plot(figsize=(18,6))
# 31days * 24hours * 60minutes = 44640
arr = [float('nan') for i in range(44640)]
for idx,v in enumerate(series):
arr[idx*144] = v
ts_start = datetime.datetime(2021,5,1).timestamp()
x = [datetime.datetime.fromtimestamp(ts_start+60*i) for i in range(len(arr))]
df = pd.DataFrame({"x": x, "y": arr})
df['y'] = df['y'].interpolate(method='linear')
df['y'] = df['y'].astype(int)
df.set_index('x').plot(figsize=(18,6))
logdir = "./logdir"
if not os.path.exists(logdir):
os.mkdir(logdir)
%%time
for idx,v in enumerate(df['y'].values):
row = []
dstart = datetime.datetime(2021,5,1) + datetime.timedelta(minutes=idx)
dstart = dstart
filename = logdir + "/" + dstart.strftime("%Y-%m-%d.log")
dstart = float(dstart.timestamp()*1000)
t = np.linspace(0, 59, v) * 1000
for i in t:
ts = int(dstart+i)
ds = datetime.datetime.fromtimestamp(ts/1000.0)
datefmt = ds.strftime("[%d/%b/%Y:%H:%M:%S.%f")[:-3] + " -0300]"
status_code = random.choice(status_codes)
path = random.choice(paths)
row.append(f"{{ \"time\":\"{datefmt}\", \"path\":\"{path}\", \"status\":\"{status_code}\" }}")
if os.path.exists(filename):
with open(filename, "a+") as f:
f.write("\n")
with open(filename, "a+") as f:
f.write("\n".join(row))
CPU times: user 1h 16min 53s, sys: 1min 16s, total: 1h 18min 10s
Wall time: 3h 28min 21s
```
```
{ "time":"[01/May/2021:00:00:00.000 -0300]", "path":"page153", "status":"302" }
{ "time":"[01/May/2021:00:00:00.001 -0300]", "path":"page112", "status":"304" }
{ "time":"[01/May/2021:00:00:00.003 -0300]", "path":"page6", "status":"408" }
{ "time":"[01/May/2021:00:00:00.005 -0300]", "path":"page54", "status":"404" }
{ "time":"[01/May/2021:00:00:00.007 -0300]", "path":"page113", "status":"304" }
{ "time":"[01/May/2021:00:00:00.009 -0300]", "path":"page81", "status":"200" }
{ "time":"[01/May/2021:00:00:00.011 -0300]", "path":"page75", "status":"302" }
{ "time":"[01/May/2021:00:00:00.013 -0300]", "path":"page147", "status":"408" }
{ "time":"[01/May/2021:00:00:00.015 -0300]", "path":"page198", "status":"404" }
```
```
2.9G logdir/2021-05-01.log
1.1G logdir/2021-05-02.log
2.3G logdir/2021-05-03.log
3.1G logdir/2021-05-04.log
1.4G logdir/2021-05-05.log
1.5G logdir/2021-05-06.log
2.7G logdir/2021-05-07.log
895M logdir/2021-05-08.log
2.2G logdir/2021-05-09.log
2.8G logdir/2021-05-10.log
870M logdir/2021-05-11.log
1.7G logdir/2021-05-12.log
3.2G logdir/2021-05-13.log
2.4G logdir/2021-05-14.log
818M logdir/2021-05-15.log
3.6G logdir/2021-05-16.log
2.2G logdir/2021-05-17.log
957M logdir/2021-05-18.log
1.8G logdir/2021-05-19.log
2.4G logdir/2021-05-20.log
963M logdir/2021-05-21.log
2.7G logdir/2021-05-22.log
2.6G logdir/2021-05-23.log
664M logdir/2021-05-24.log
2.8G logdir/2021-05-25.log
3.8G logdir/2021-05-26.log
1.2G logdir/2021-05-27.log
2.7G logdir/2021-05-28.log
3.3G logdir/2021-05-29.log
1.4G logdir/2021-05-30.log
2.0G logdir/2021-05-31.log
```
# ELK
## Logstash
### install
```shell
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cat <
/etc/yum.repos.d/logstash.repo
[logstash-7.x]
name=Elastic repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-md
EOF
yum -y install logstash
echo "export PATH=\"/usr/share/logstash/bin/:$PATH\"" >> /root/.bashrc
export PATH="/usr/share/logstash/bin/:$PATH"
```
### config
`logstash.conf`
```
input {
file {
path => "/root/wkdir/logs/*.log"
start_position => "beginning"
#codec => multiline {
# pattern => '.*128=.*'
# negate => false
# what => previous
#}
sincedb_path => "/dev/null"
}
}
# https://stackoverflow.com/questions/27443392/how-can-i-have-logstash-drop-all-events-that-do-not-match-a-group-of-regular-exp
filter {
grok {
add_tag => [ "valid" ]
match => {
"message" => [
".*?"time":"(?P