Exam preparation
https://aws.amazon.com/certification/certified-data-analytics-specialty/
https://www.aws.training/Certification
- CTC Centro de Treinamento e Certificacao (AMP) (WBD)
- (11) 2338-3292 (presencial)
InLearn Educacao Ltda (NT)(fechou)- (11) 4064-0200 (a partir dia 15/06)
- Green Tecnologia (WBD)
- (11) 3253-5299
- InforMaker SP* - IE-Kiosk-1277 <- Paulista
- Tel.: +55 11 3020-6339 3555-1585
-
https://www.whizlabs.com/learn/course/aws-certified-data-analytics-specialty
- https://medium.com/@yared94/how-i-passed-the-aws-data-analytics-specialty-certification-46a6c838a80
- Udemy Data Stephane + Frank
- Whizlabs
- ..
- Designing Data-Intensive Applications by Martin Kleppman
- https://medium.com/@lwbayes91/how-i-prepared-for-the-aws-data-analytics-specialist-exam-9a1465814aa9
- You are designing solution for a company in xxx domain. Data is generated in xxx system at xxx rate, and you need to design a solution for xxx use case, at xxx constraint (latency, capacity, order of event data), and you need to prioritize cost/low maintenance/lack of technical skill. How would you design the solution?
- One needs to have a good understanding of the various dimensions of characteristics of AWS services covered to answer these questions effectively. For example:
- Latency: what services can achieve ~10 seconds latency? (Pop quiz: Can Kinese Data Streams do it? What about Data Firehose?) What about a minute / near real time? If I have X amount of on-prem data to move to AWS and I need it in y days, should I use Snowball or Direct Connect?
- One needs to have a good understanding of the various dimensions of characteristics of AWS services covered to answer these questions effectively. For example:
- You are designing solution for a company in xxx domain. Data is generated in xxx system at xxx rate, and you need to design a solution for xxx use case, at xxx constraint (latency, capacity, order of event data), and you need to prioritize cost/low maintenance/lack of technical skill. How would you design the solution?

layout: post title: “AWS Certified Data Analytics - Specialty Journey” comments: true date: “2020-08-19 23:45:08.362000+00:00” —
https://aws.amazon.com/certification/certified-data-analytics-specialty/

- AWS Exam Readiness
- https://aws.amazon.com/certification/certification-prep/?nc2=sb_ce_ep
- Whitepapers
- FAQs
AWS Certified Data Analytics Specialty 2021 - Hands On!
https://udemy.com/course/aws-data-analytics/

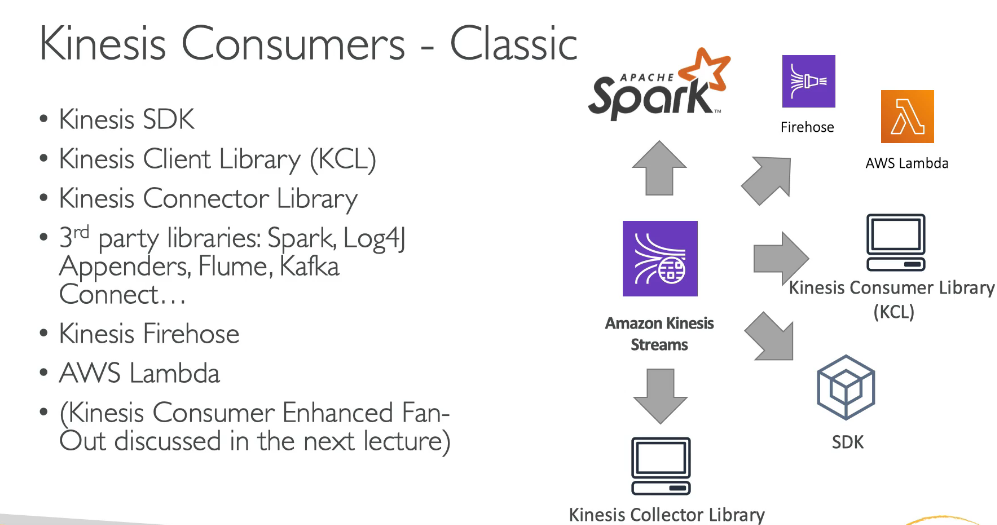
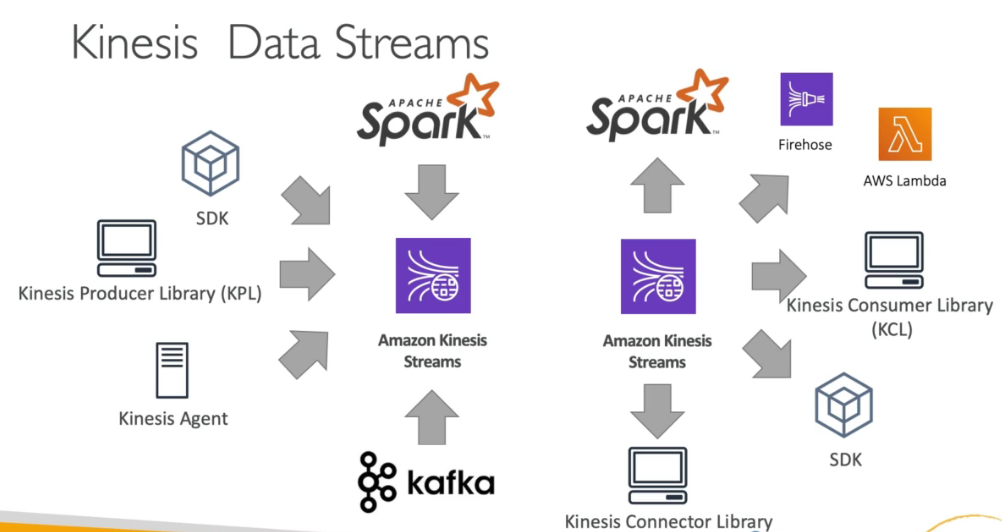
- AWS Kinesis Overview
- Kinesis is a managed alternative to Apache Kafka
- Great for application logs, metrics, IoT, clickstreams
- Great for “real-time” big data
- Great for streaming processing frameworks (spark, nifi)
- Data is automatically replicated synchronously do 3 AZ
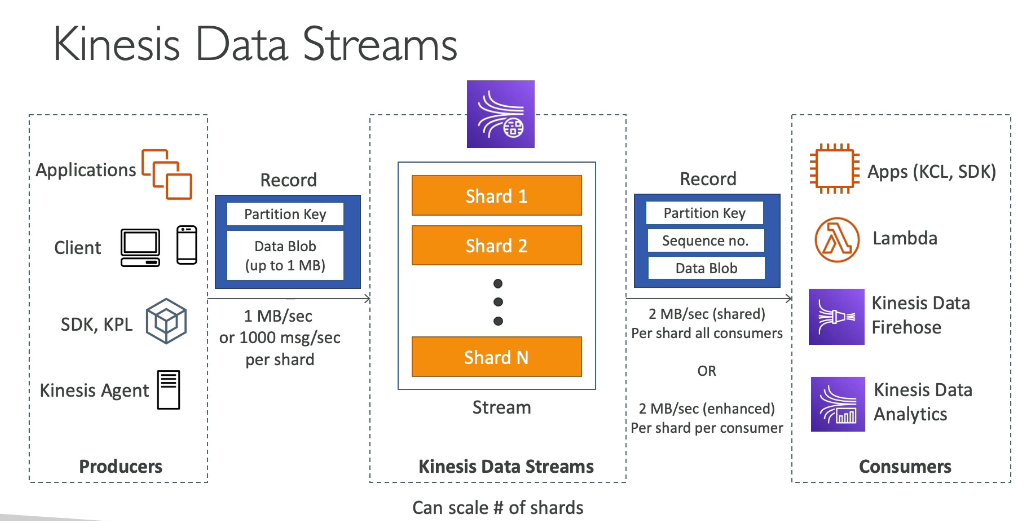
- Kinesis Streams: low latency streaming ingest at scale
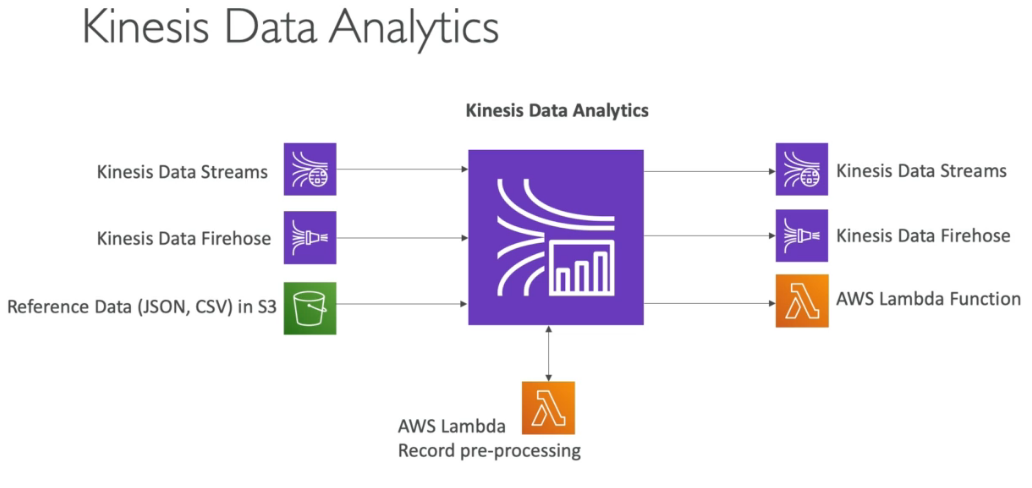
- Kinesis Analytics: perform real-time analytics on streams using SQL
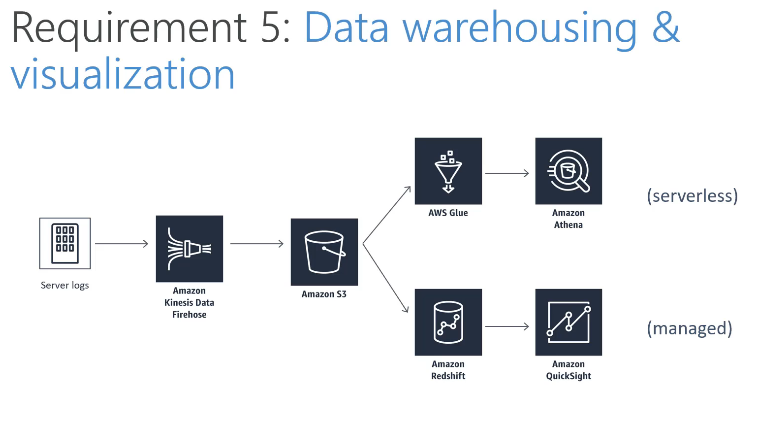
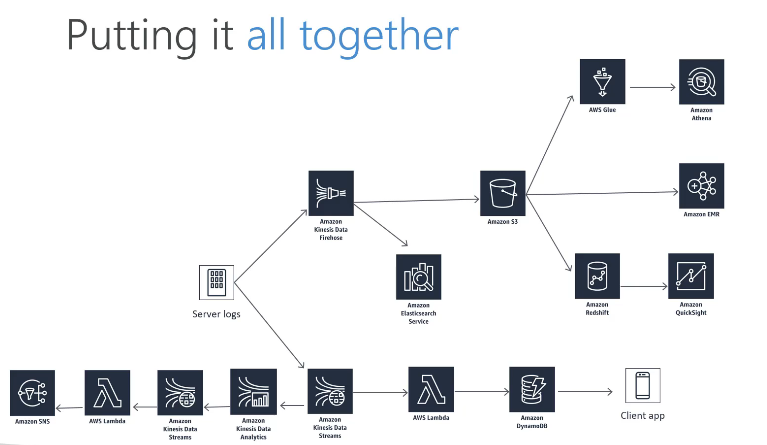
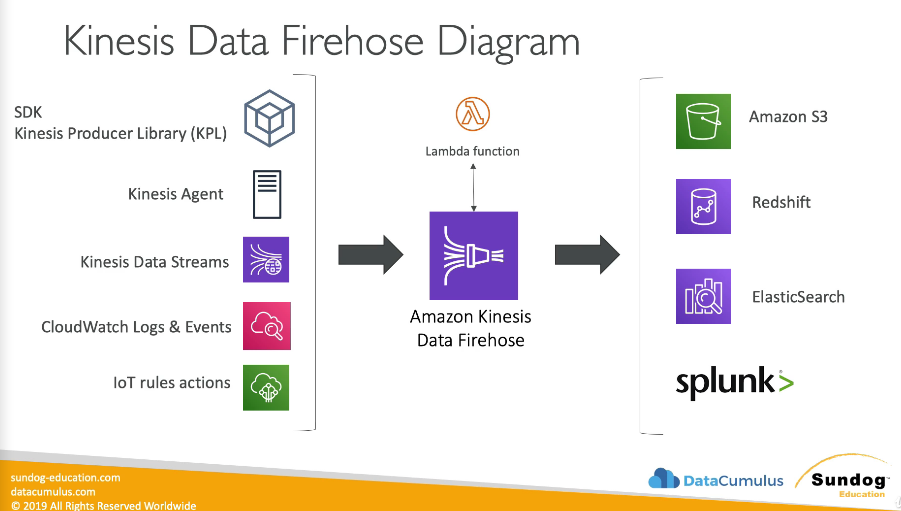
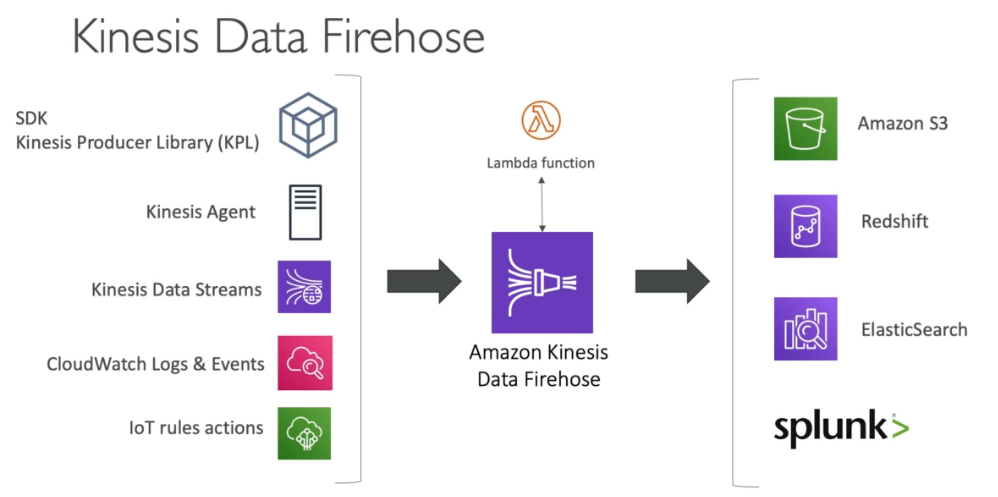
- Kinesis Firehose: load streams into S3, Redshift, ElasticSearch & Splunk






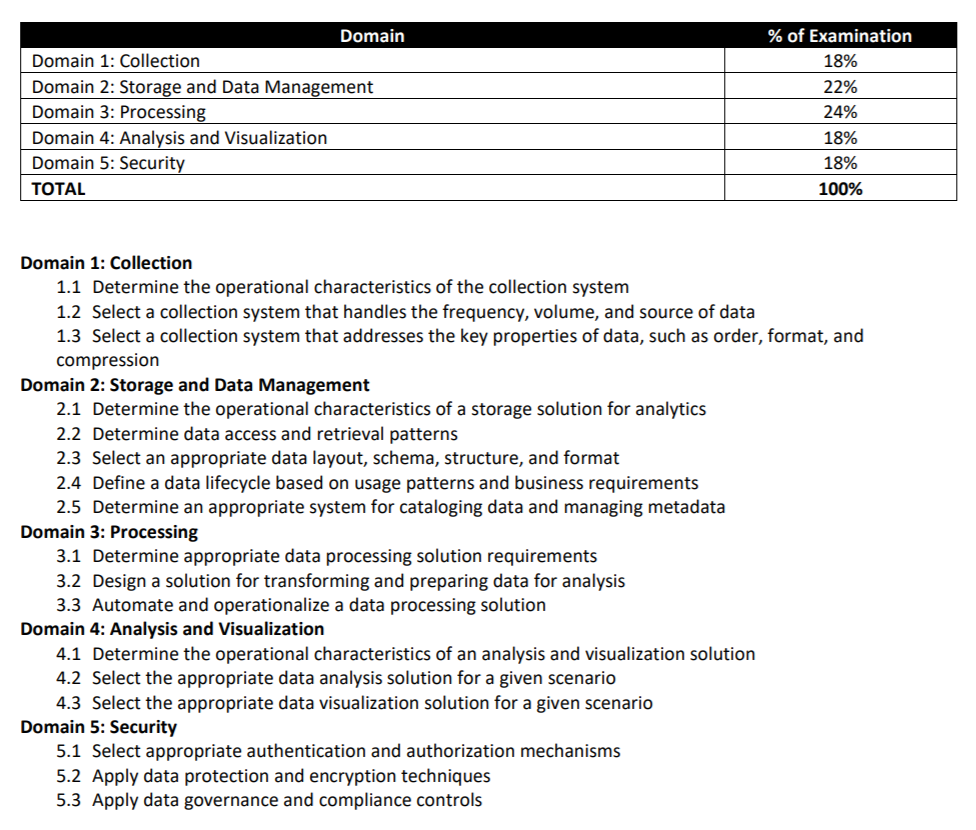
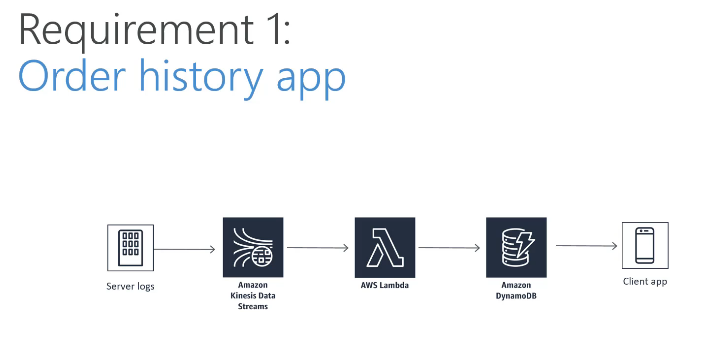
Domain 1: Collection



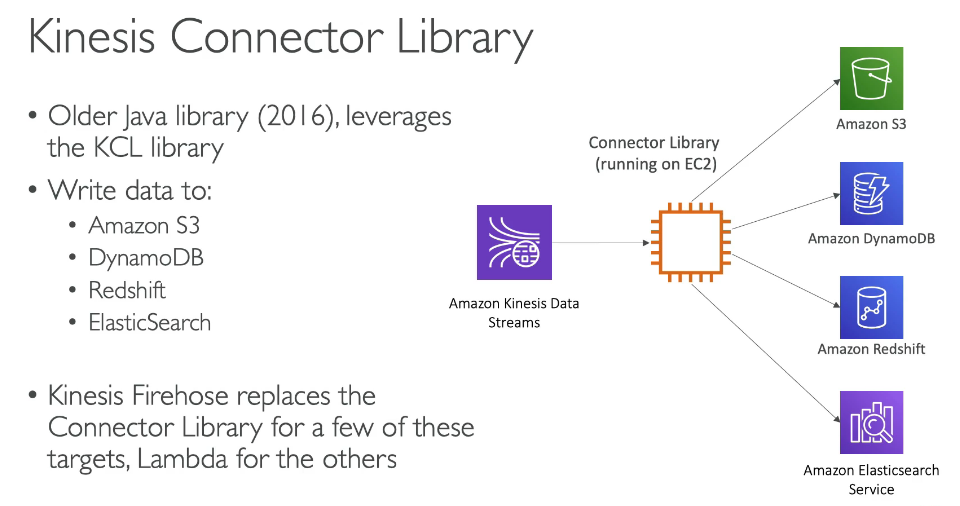
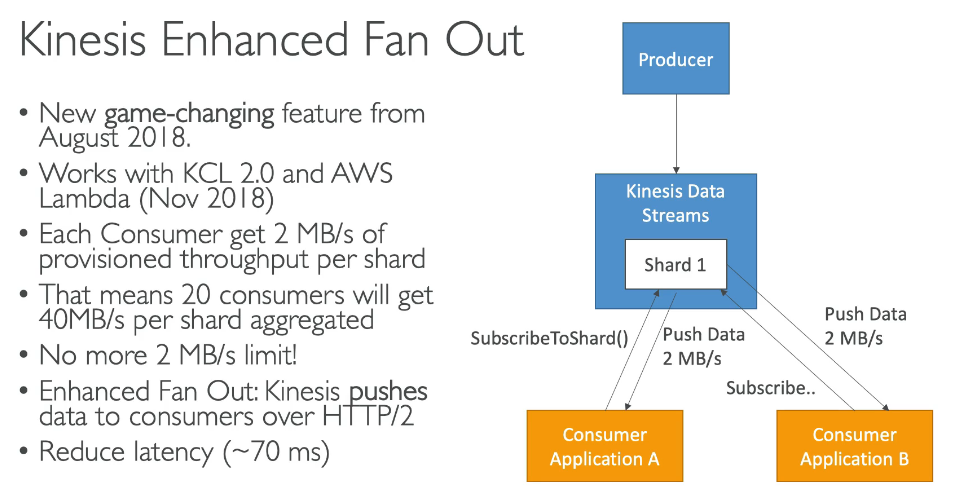
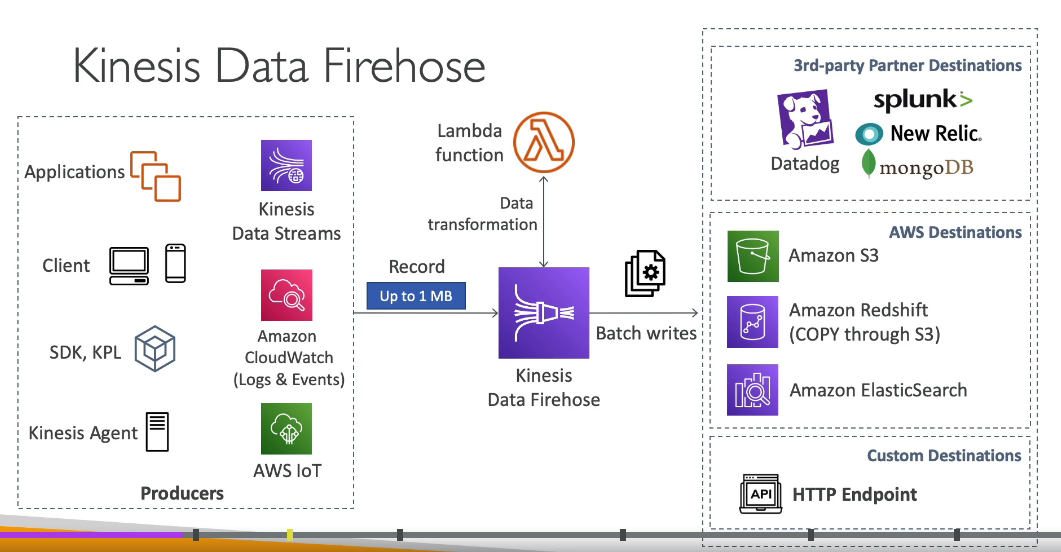

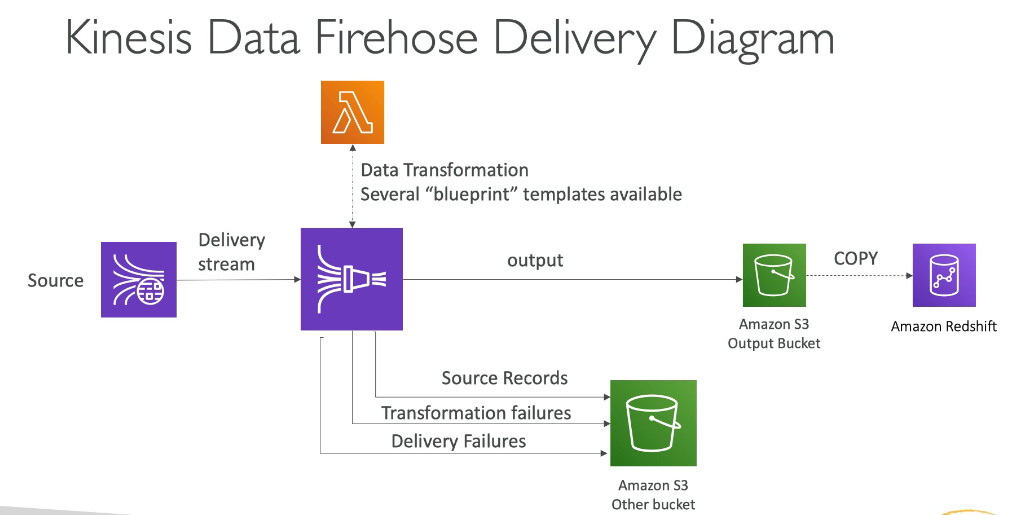


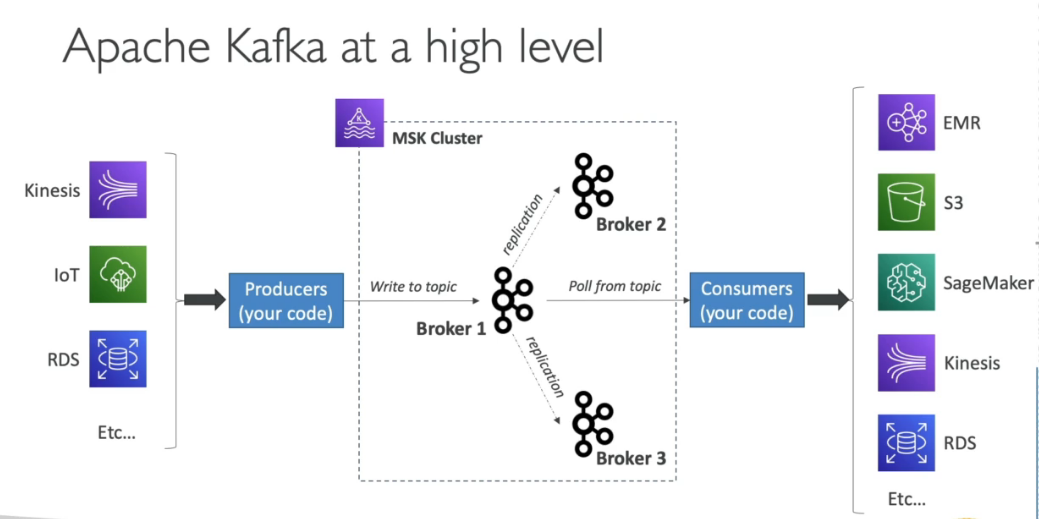

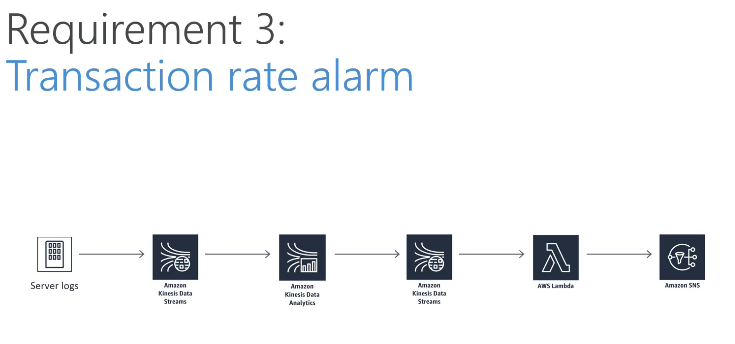
Domain 3: Processing
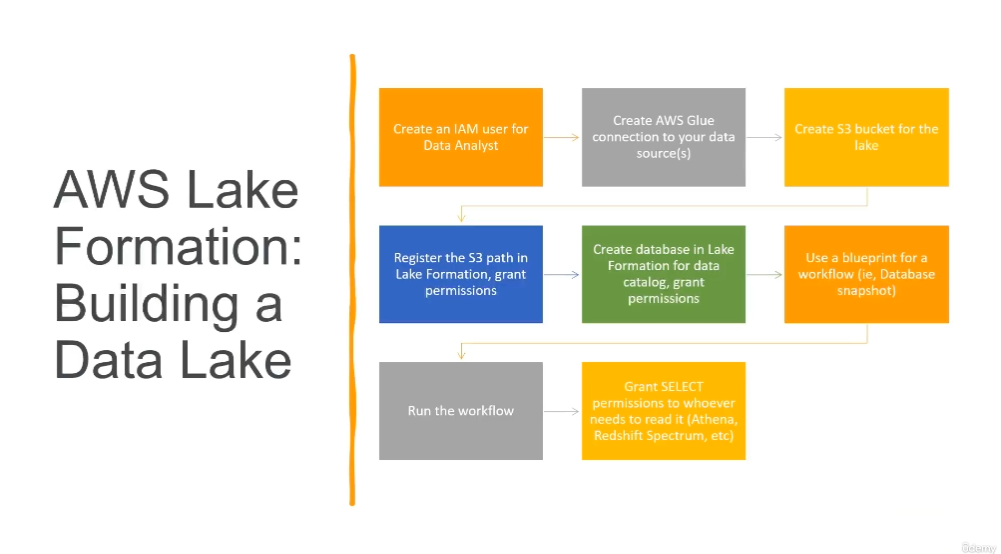
AWS Lake Formation


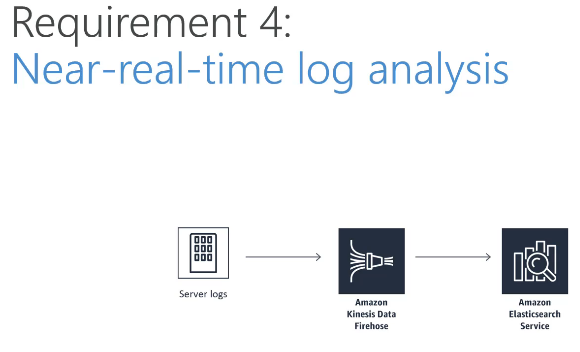
Domain 4: Analysis
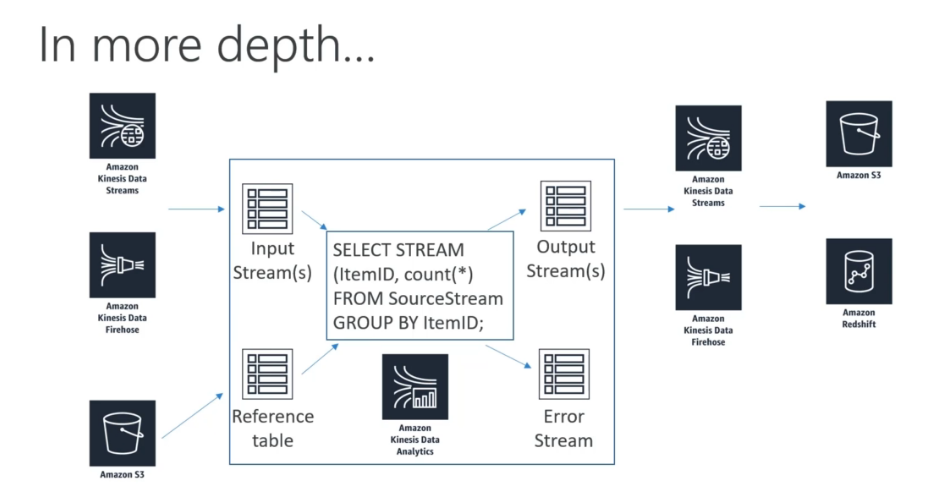
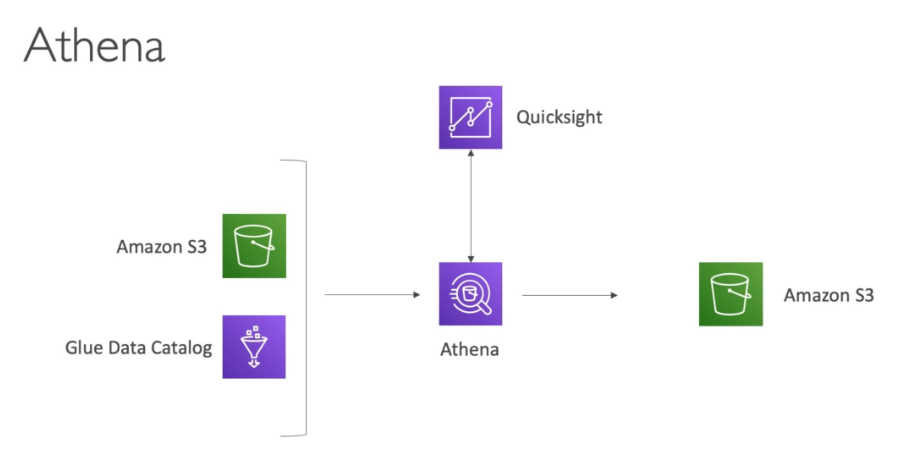
Athena

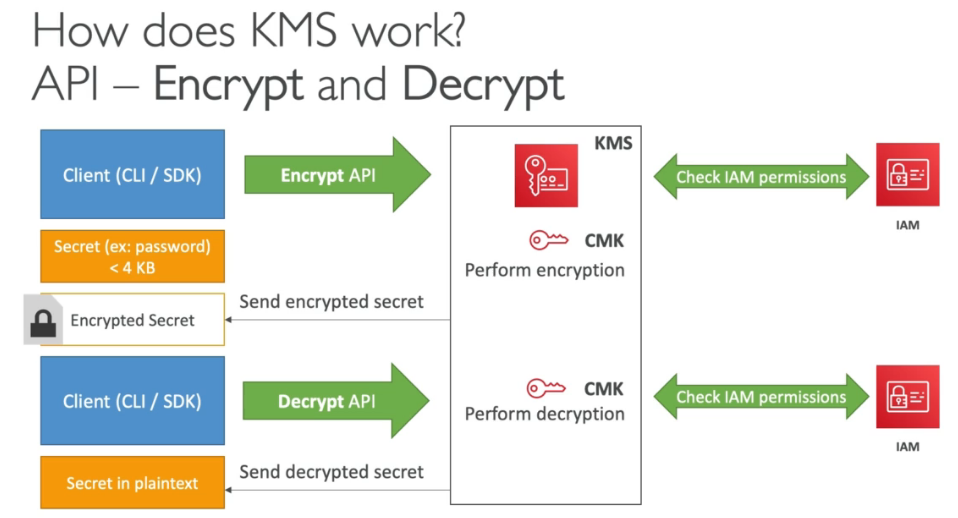
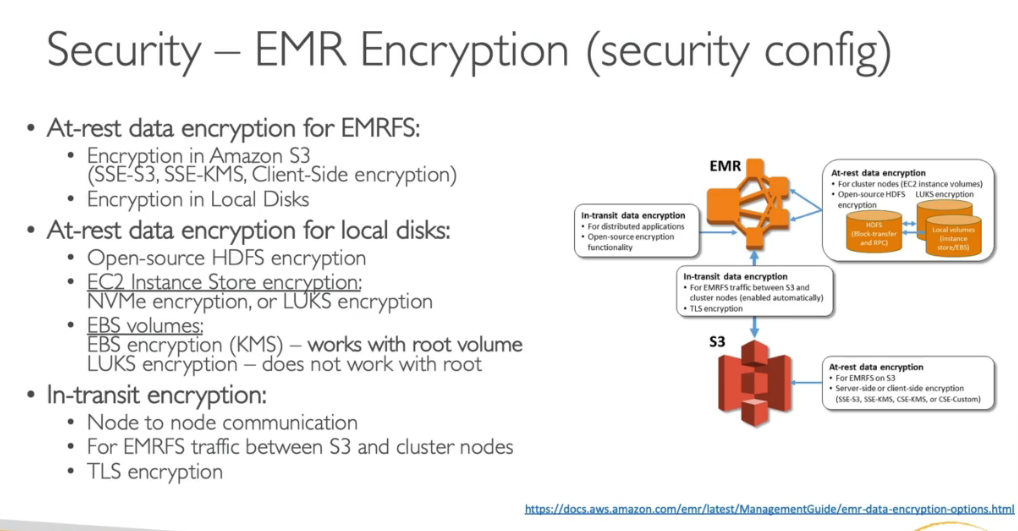
Domain 7: Security
KMS
AWS Services Security Deep Dive (1/3)





AWS Services Security Deep Dive (2/3)









Policies - Advanced

Section 8: Everything Else
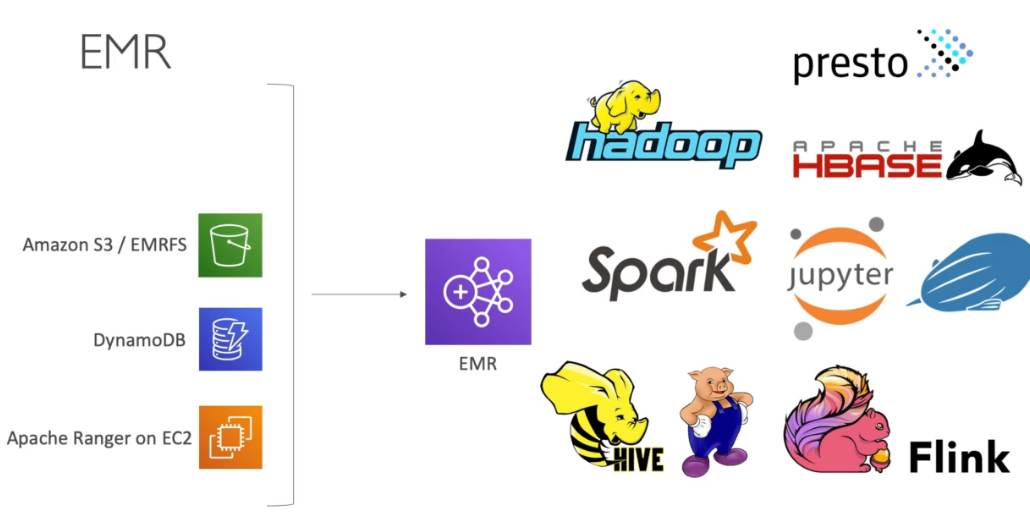
Instance Types for Big Data

Prep

Practice Exam
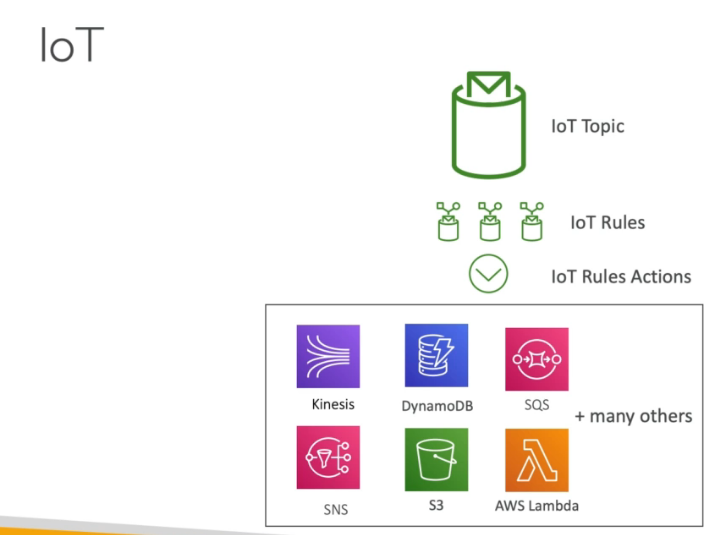
- Of the 4 four types of identity principals for authentication supported by AWS IoT, which one is commonly used by mobile applications?
- Cognito Identities
- You need to load several hundred GB of data every day from Amazon S3 into Amazon Redshift, which is stored in a single file. You’ve found that loading this data is prohibitively slow. Which approach would optimize this loading best?
- Split the data into files between 1MB and 125MB (after compression,) and specify GZIP compression from multiple COPY commands run concurrently.
- Explanation
- Multiple concurrent COPY commands might sound like a good idea, but in reality it forces Redshift to perform a slow, serialized load followed by a VACUUM process. If you want to load data in parallel, it’s best to split your data into separate files no more than 1GB apiece. Compressing the data also helps. Loading data in the same order as your sort key can also speed up the import process, which is the opposite of “Avoid loading the data in the same order as your sort key”.
- A real estate company wishes to display interactive charts on their public-facing website summarizing their prior month’s sales activity. Which TWO solutions would provide this capability in a scalable and inexpensive manner? Embed Amazon Quicksight into the website, querying an underlying Redshift data warehouse.
- Publish data in csv format to Amazon Cloudfront via S3, and use Highcharts to visualize the data on the web.
- Publish data in csv format to Amazon Cloudfront via S3, and use d3.js to visualize the data on the web.
- Explanation
- Both d3 and Highcharts are Javascript libraries intended for interactive charts and graphs on websites. Quicksight and Tableau are data analysis tools not intended for public deployment. While it is possible to embed Quicksight in a website, Quicksight charges on a per-user basis and the costs involved with exposing it to the general public would be prohibitive (not to mention everyone would need an account to view it.)
- You are creating an EMR cluster that will process the data in several MapReduce steps. Currently you are working against the data in S3 using EMRFS, but the network costs are extremely high as the processes write back temporary data to S3 before reading it. You are tasked with optimizing the process and bringing the cost down, what should you do?
- Add a preliminary step that will use a S3DistCp command
-
Here, using an S3DistCp command is the right thing to do to copy data from S3 into HDFS and then make sure the data is processed locally by the EMR cluster MapReduce job. Upon completion, you will use S3DistCp again to push back the final result data to S3. LUKS encryption will not help, EMRFS does not have a local caching feature, and changing the EC2 instance types won’t help
- A manager wishes to make a case for hiring more people in her department, by showing that the number of incoming tasks for her department have grown at a faster rate than other departments over the past year. Which type of graph in Amazon Quicksight would be best suited to illustrate this data? A sequence of slides in a QuickSight Story
- Area line chart
-
When you’re looking for trends over time, line charts are usually the right choice.
- What are THREE ways in which EMR integrates Pig with Amazon S3?
- Submitting work from the EMR console using Pig scripts stored in S3
- Directly writing to HCatalog tables in S3
- Loading custom JAR files from S3 with the REGISTER command
You can configure EMRFS, backed by S3, as your data store in Pig, which allows it to read and write to S3 as it would with HDFS.
- You are storing gaming data for your game that is becoming increasingly popular. An average game data will contain 80KB of data and as your games are quick. You expect about 400 games to be written per second to your database. Additionally, a lot of people would like to retrieve this game data and you expect about 1800 eventually consistent reads per second. How should you provision your DynamoDB table?
- 32000 WCU & 18000 RCU
1 WCU = 1 KB / s so we need 80KB * 400 / s = 32000 WCU. 1 RCU = 2 eventually consistent reads per second of 4 KB so we need 1800 * 80 / 8 = 18000 RCU.
- 32000 WCU & 18000 RCU
- A produce export company has multi-dimensional data for all of its shipments, such as the date, price, category, and destination of every shipment. A data analyst wishes to explore this data, with the primary purpose of looking for trends and outliers in the information. Which QuickSight visualization would be best suited for this?
- Heat map
You can think of heat maps as pivot tables that highlight outliers and trends using color.
- Heat map
- You are tasked with using Hive on Elastic MapReduce to analyze data that is currently stored in a large relational database. Which approach could meet this requirement?
- Use Apache Sqoop on the EMR cluster to copy the data into HDFS
Sqoop is an open-source system for transferring data between Hadoop and relational databases. Flume is intended for real-time streaming applications, Glue is intended for use with S3, and you can’t direct EMRFS to arbitrary S3 buckets.
- Use Apache Sqoop on the EMR cluster to copy the data into HDFS
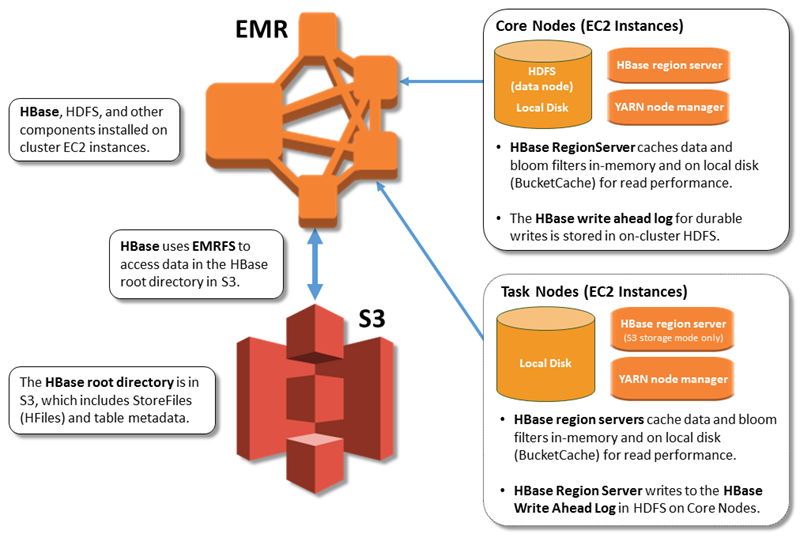
- What are THREE ways in which EMR optionally integrates HBase with S3?
- Snapshots of HBase data to S3
- HBase read-replicas on S3
- Storage of HBase StoreFiles and metadata on S3
EMR allows you use S3 instead of HDFS for HBase’s data via EMRFS. Although you can export snapshots to S3, HBase itself does not automate this for you.
- You are processing data using a long running EMR cluster and you like to ensure that you can recover data in case an entire availability zone goes down, as well as process the data locally for the various Hive jobs you plan on running. What do you recommend to do this at a minimal cost?
- Store the data in S3 and keep a warm copy in HDFS
EBS backups will be expensive and very painful to deal with as the dataset will be distributed over many different snapshots due to HDFS block replication mechanisms. Storing all the data in S3 and none in HDFS will incur some extra costs as the data is constantly read and written back to S3. It’s better to keep a local copy on HDFS. Finally, maintaining an entirely new EMR cluster for disaster recovery is too expensive.
- Store the data in S3 and keep a warm copy in HDFS
- You work for a gaming company and each game’s data is stored in DynamoDB tables. In order to provide a game search functionality to your users, you need to move that data over to ElasticSearch. How can you achieve it efficiently and as close to real time as possible?
- Enable DynamoDB Streams and write a Lambda function
DynamoDB Streams do not have direct integration with Firehose, DataPipeline will not have the data fast enough into ElasticSearch, and DynamoDB Global Tables do not integrate with ElasticSearch. Here we need to write a Lambda function that is triggered from a DynamoDB Stream
- Enable DynamoDB Streams and write a Lambda function
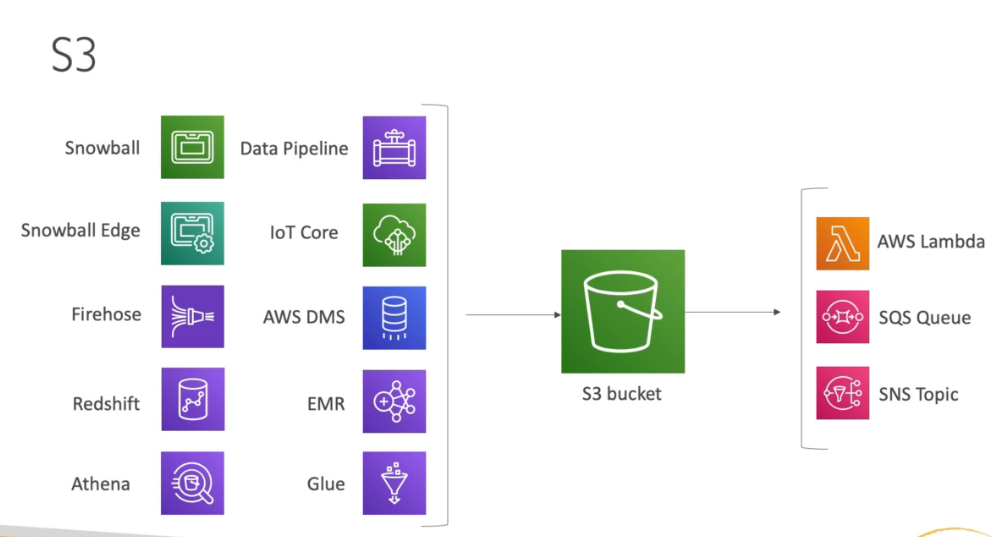
- Your company collects data from various sources into Kinesis and the stream is delivered using Kinesis Data Firehose into S3. Once in S3, your data scientist team uses Athena to query the most recent data, and usage has shown that after a month, the team queries the data less and less, and finally after two months does not use it. For regulatory reasons, it is required to keep all the data for 5 years and no one should be able to delete it. What do you recommend? (select two)
- Create a lifecycle rule to migrate all the data to S3 IA after 30 days and delete the data after 60 days. Create a rule to have a replica of all source data into Glacier from the first day.
- Implement a Glacier Vault Lock Policy
S3 Athena is not a storage class. Data should be moved to S3 IA after 30 days. If the data is moved to Glacier after 60 days, then there are no guarantees for it not to be deleted by anyone for the first 60 days. Hence a replica of the data should be delivered to Glacier right away. Finally, to prevent deletion in Glacier, you must use a Glacier Vault Lock Policy.
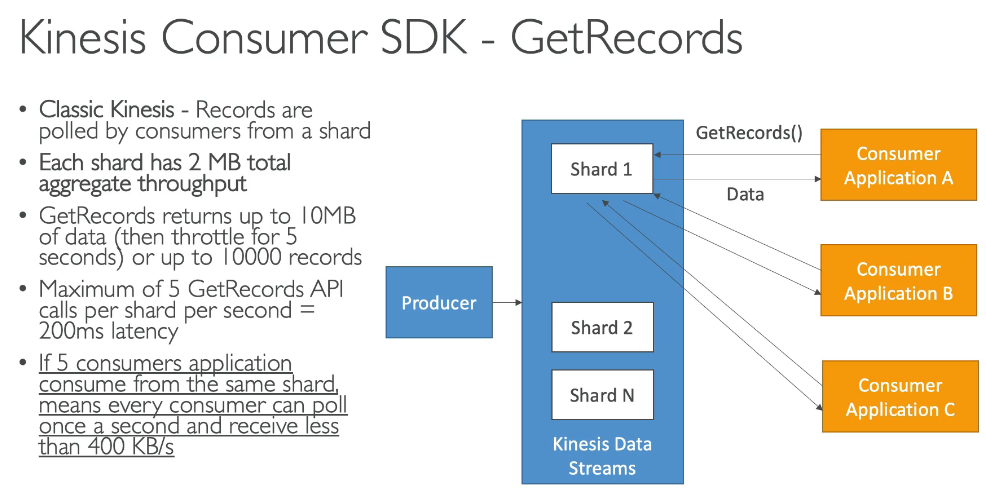
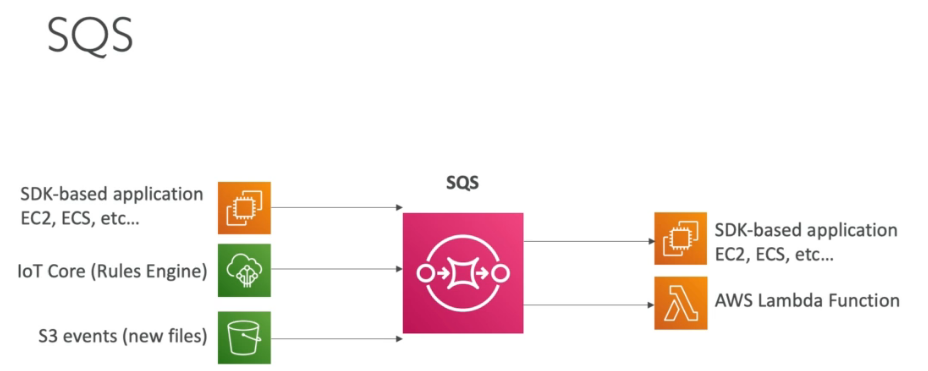
- You would like to process data coming from IoT devices, and processing that data takes approximately 2 minutes per data point. You would also like to be able to scale in terms of number of processes that will consume that data, based on the load your are receiving, and no ordering constraints are required. What do you recommend?
- Define an IoT rules actions to send data to SQS and consume the data with EC2 instances in an Auto Scaling group
Kinesis Data Streams doesn’t work because it doesn’t scale as the load increases. Kinesis Data Firehose doesn’t work as Lambda cannot be a consumer of KDF. Lambda can only be used for transformations of data going through KDF before being delivered to S3, Redshift, ElasticSearch or Splunk. Here the lack of ordering and the fact the processing may be long, and needs to scale based on the number of messages make SQS a great fit, that will also be more cost efficient
- Your daily Spark jobs runs against files created by a Kinesis Firehose pipeline in S3. Due to a low throughput, you observe that each of the many files created by Kinesis Firehose is about 100KB. You would like to optimise your Spark job as best as possible to query the data efficiently. What do you recommend?
- Consolidate files on a daily basis using DataPipeline
Multi part download is not a Spark feature, which does not deal well with many small files. GZIP will not solve the problems, the files will still be small and you will have many of them. Kinesis Data Firehose does not have a flush time greater than 5 minutes, which will still create many small files. Bottom line, you should use a DataPipeline job to consolidate the files on a daily basis into a larger file.
- Consolidate files on a daily basis using DataPipeline
- Your enterprise would like to leverage AWS Redshift to query data. Currently that data is produced at the rate of 5 PB of historical data and another 3 TB per month. The non-historical, ongoing data should be available with less than two days delay. You are tasked with finding the most efficient data transfer solution into S3. What do you recommend? (select two)
- Establish Direct Connect and do a daily upload newly created monthly data directly into S3
- Use Snowball to transfer the historical data
Snowball is the only way to transfer your historical data as it would take a very long time to transfer over the network, even with Direct Connect or Site-to-Site VPN. For ongoing data, it’s the equivalent of 100 GB a day, which will take less than an hour to upload each day, versus Snowball which will definitely take longer than 2 days to reach AWS.
- You have created a system that recommends items similar to other items on an e-commerce website, by training a recommender system using Mahout on an EMR cluster. Which would be a performant means to vend the resulting table of similar items for any given item to the website at high transaction rates?
- Publish the data into HBase
This is an OLTP use case for which a “NoSQL” database is a good fit. HBase is the only option presented designed for OLTP and not OLAP, plus it has the advantage of already being present in EMR. DynamoDB would also be an appropriate technology to use.
- Publish the data into HBase
- What security mechanisms are supported by EMR? (Select three)
- LUKS encryption
- SSE-KMS
- KMS encryption
https://aws.amazon.com/blogs/big-data/best-practices-for-securing-amazon-emr/
- As an e-commerce retailer, you would like to onboard clickstream data onto Kinesis from your web servers Java applications. You want to ensure that a retry mechanism is in place, as well as good batching capability and asynchronous mode. You also want to collect server logs with the same constraints. What do you recommend?
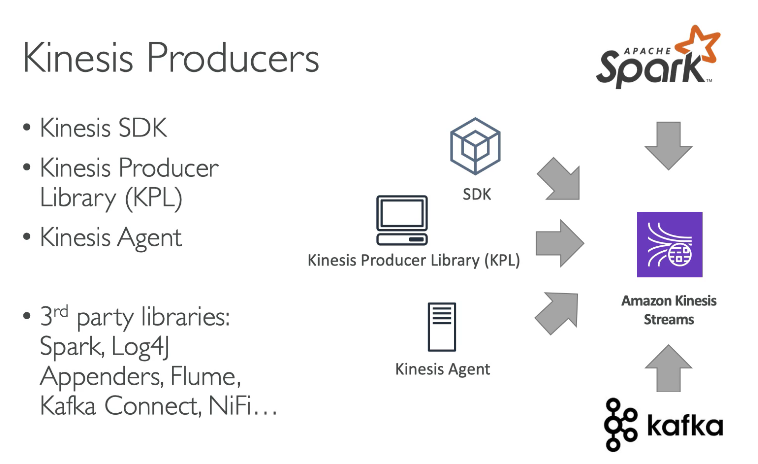
- Use the Kinesis Producer Library to send the clickstream and the Kinesis agent to collect the Server Logs
The KPL has the mechanisms in place for retry and batching, as well as asynchronous mode. The Kinesis agent is meant to retrieve server logs with just configuration files.
- Use the Kinesis Producer Library to send the clickstream and the Kinesis agent to collect the Server Logs
cheat sheets
https://tutorialsdojo.com/aws-cheat-sheets/

Appendix
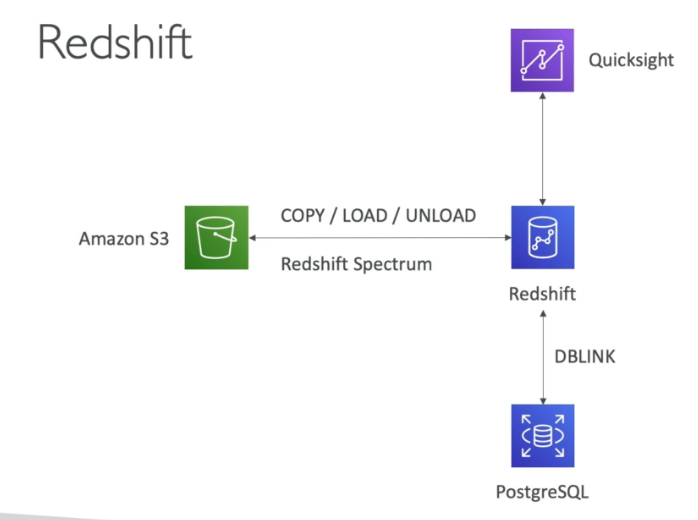
- Redshift scaling
- Elastic resize – To quickly add or remove nodes from an existing cluster, use elastic resize. You can use it to change the node type, number of nodes, or both. If you only change the number of nodes then queries are temporarily paused and connections are held open if possible. During the resize operation, the cluster is read-only. Typically, elastic resize takes 10–15 minutes.
- Classic resize – Use classic resize to change the node type, number of nodes, or both. Choose this option when you are resizing to a configuration that isn’t available through elastic resize. A classic resize copies tables to a new cluster. The source cluster will be in read-only mode until the resize operation finishes. An example is to or from a single-node cluster. During the resize operation, the cluster is read-only. Typically, classic resize takes 2 hours–2 days or longer, depending on your data’s size.
- Snapshot and restore with classic resize – To keep your cluster available during a classic resize, you can first make a copy of an existing cluster, then resize the new cluster. Keep in mind that all data written to the source cluster after the snapshot is taken must be manually copied to the target cluster after the migration.
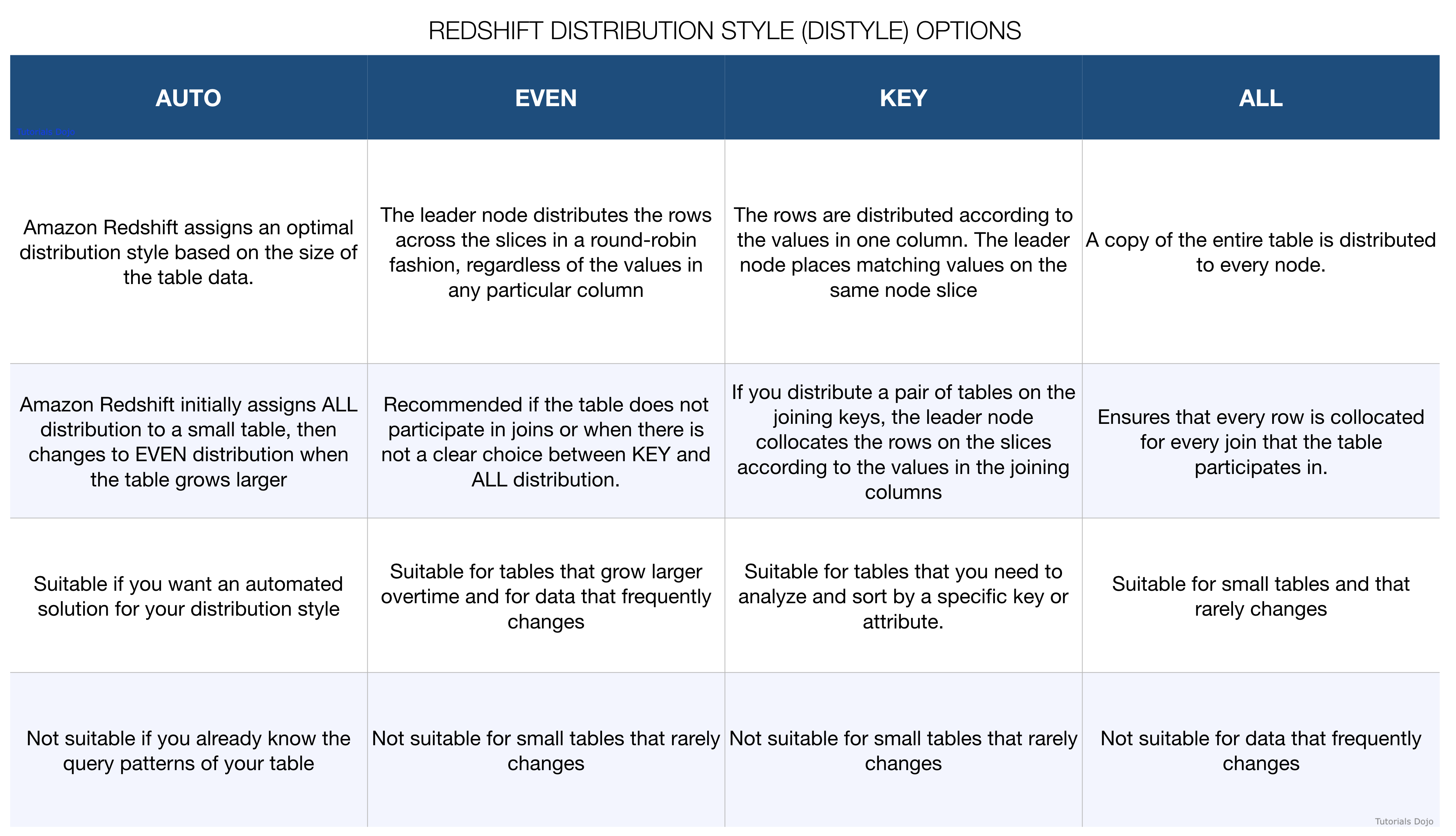
- Redshift DISTSTYLE
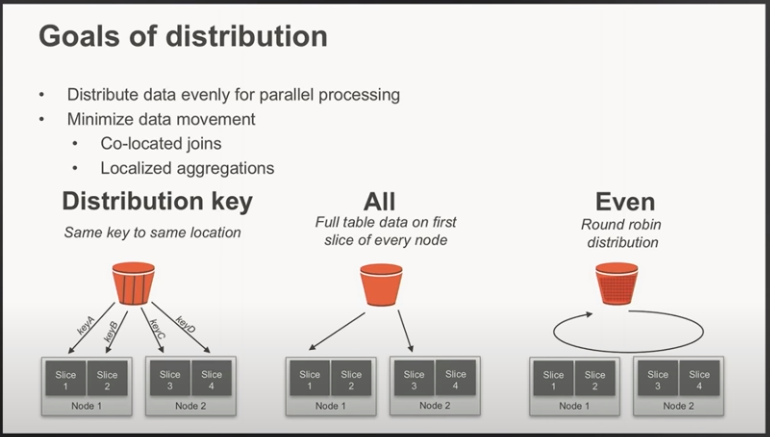
- DISTSTYLE defines the data distribution style for the whole table. Amazon Redshift distributes the rows of a table to the compute nodes according the distribution style specified for the table. The distribution style that you select for tables affects the overall performance of your database.
- DISTSTYLE EVEN – The leader node distributes the rows across the slices in a round-robin fashion, regardless of the values in any particular column. EVEN distribution is appropriate when a table does not participate in joins or when there is not a clear choice between KEY distribution and ALL distribution.
- DISTSTYLE KEY – The rows are distributed according to the values in one column. The leader node places matching values on the same node slice. If you distribute a pair of tables on the joining keys, the leader node collocates the rows on the slices according to the values in the joining columns so that matching values from the common columns are physically stored together.
- DISTSTYLE ALL – A copy of the entire table is distributed to every node. Where EVEN distribution or KEY distribution place only a portion of a table’s rows on each node, ALL distribution ensures that every row is collocated for every join that the table participates in. ALL distribution is appropriate only for relatively slow-moving tables; that is, tables that are not updated frequently or extensively. Because the cost of redistributing small tables during a query is low, there isn’t a significant benefit to define small dimension tables as DISTSTYLE ALL.
- Redshift Resize:
- Elastic resize – Use elastic resize to change the node type, number of nodes, or both. If you only change the number of nodes, then queries are temporarily paused and connections are held open if possible. During the resize operation, the cluster is read-only. Typically, elastic resize takes 10–15 minutes. AWS recommends using elastic resize when possible.
- Classic resize – Use classic resize to change the node type, number of nodes, or both. Choose this option when you are resizing to a configuration that isn’t available through elastic resize. An example is to or from a single-node cluster. During the resize operation, the cluster is read-only. Typically, classic resize takes 2 hours–2 days or longer, depending on your data’s size.
- Snapshot and restore with classic resize – To keep your cluster available during a classic resize, you can first make a copy of an existing cluster, then resize the new cluster.
- https://aws.amazon.com/about-aws/whats-new/2020/04/amazon-redshift-now-supports-changing-node-types-within-minutes-with-elastic-resize/
- Amazon Redshift now supports elastic resize across node types. Customers can change node types within minutes and with one simple operation using elastic resize.
- Elastic resize across node type automates the steps of taking a snapshot, creating a new cluster, deleting the old cluster, and renaming the new cluster into a simple, quick, and familiar operation. Elastic resize operation can be run at any time or can be scheduled to run at a future time. Customers can quickly upgrade their existing DS2 or DC2 node type-based cluster to the new RA3 node type with elastic resize.
- Redshift Autit Logging:
- Connection Log - Logs authentication attempts, and connections and disconnections
- User log - logs information about changes to database user definitions
- User activity log - logs each query before it is run on the database
- Kinesis Data Analytics - Query WindowA
- Stagger Windows: A query that aggregates data using keyed time-based windows that open as data arrives. The keys allow for multiple overlapping windows. This is the recommended way to aggregate data using time-based windows, because Stagger Windows reduce late or out-of-order data compared to Tumbling windows.
- Tumbling Windows: A query that aggregates data using distinct time-based windows that open and close at regular intervals.
- Sliding Windows: A query that aggregates data continuously, using a fixed time or rowcount interval.

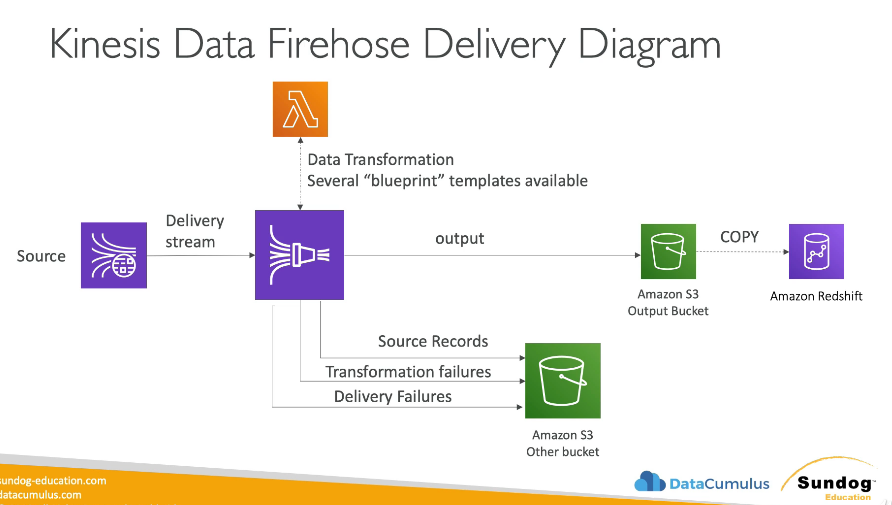
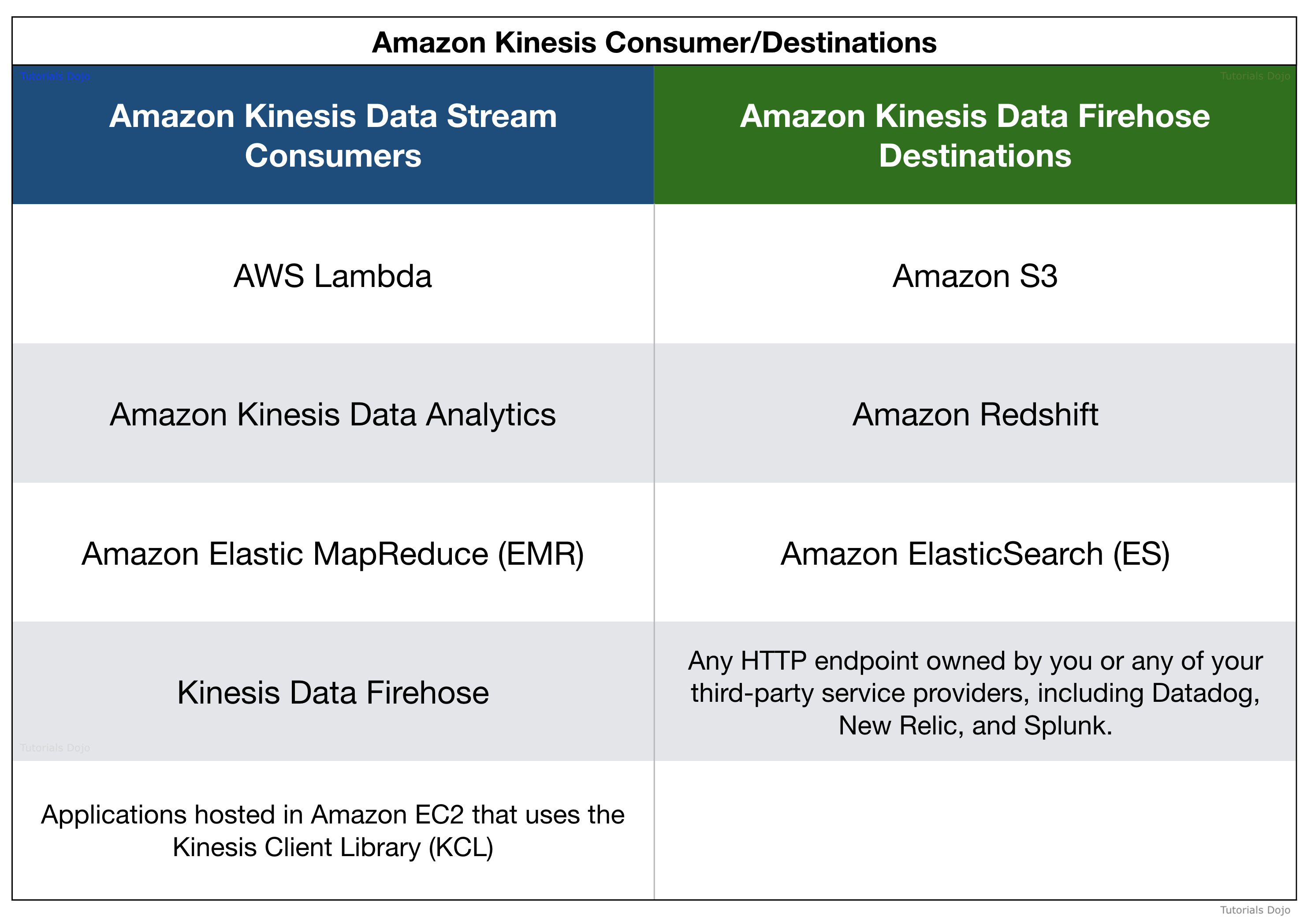
- Kinesis Firehose can send data to
- S3
- Redshift
- Elasticsearch
- Splunk
- Blueprints and Workflows in Lake Formation
- Database snapshot – Loads or reloads data from all tables into the data lake from a JDBC source. You can exclude some data from the source based on an exclude pattern.
- Use when:
- Schema evolution is flexible. (Columns are re-named, previous columns are deleted, and new columns are added in their place.)
- Complete consistency is needed between the source and the destination.
- Use when:
- Incremental database – Loads only new data into the data lake from a JDBC source, based on previously set bookmarks. You specify the individual tables in the JDBC source database to include. For each table, you choose the bookmark columns and bookmark sort order to keep track of data that has previously been loaded. The first time that you run an incremental database blueprint against a set of tables, the workflow loads all data from the tables and sets bookmarks for the next incremental database blueprint run. You can therefore use an incremental database blueprint instead of the database snapshot blueprint to load all data, provided that you specify each table in the data source as a parameter.
- Use when:
- Schema evolution is incremental. (There is only successive addition of columns.)
- Only new rows are added; previous rows are not updated.
- Use when:
- Log file – Bulk loads data from log file sources, including AWS CloudTrail, Elastic Load Balancing logs, and Application Load Balancer logs.
- Database snapshot – Loads or reloads data from all tables into the data lake from a JDBC source. You can exclude some data from the source based on an exclude pattern.
- Amazon EMR HBase
- AWS Glue Resource Policies vs Apache Ranger
- https://aws.amazon.com/blogs/big-data/building-securing-and-managing-data-lakes-with-aws-lake-formation/
- Many customers use AWS Glue Data Catalog resource policies to configure and control metadata access to their data. Some choose to use Apache Ranger. But these approaches can be painful and limiting. S3 policies provide at best table-level access. And you must maintain data and metadata policies separately. With Apache Ranger, you can configure metadata access to only one cluster at a time. Also, policies can become wordy as the number of users and teams accessing the data lake grows within an organization.
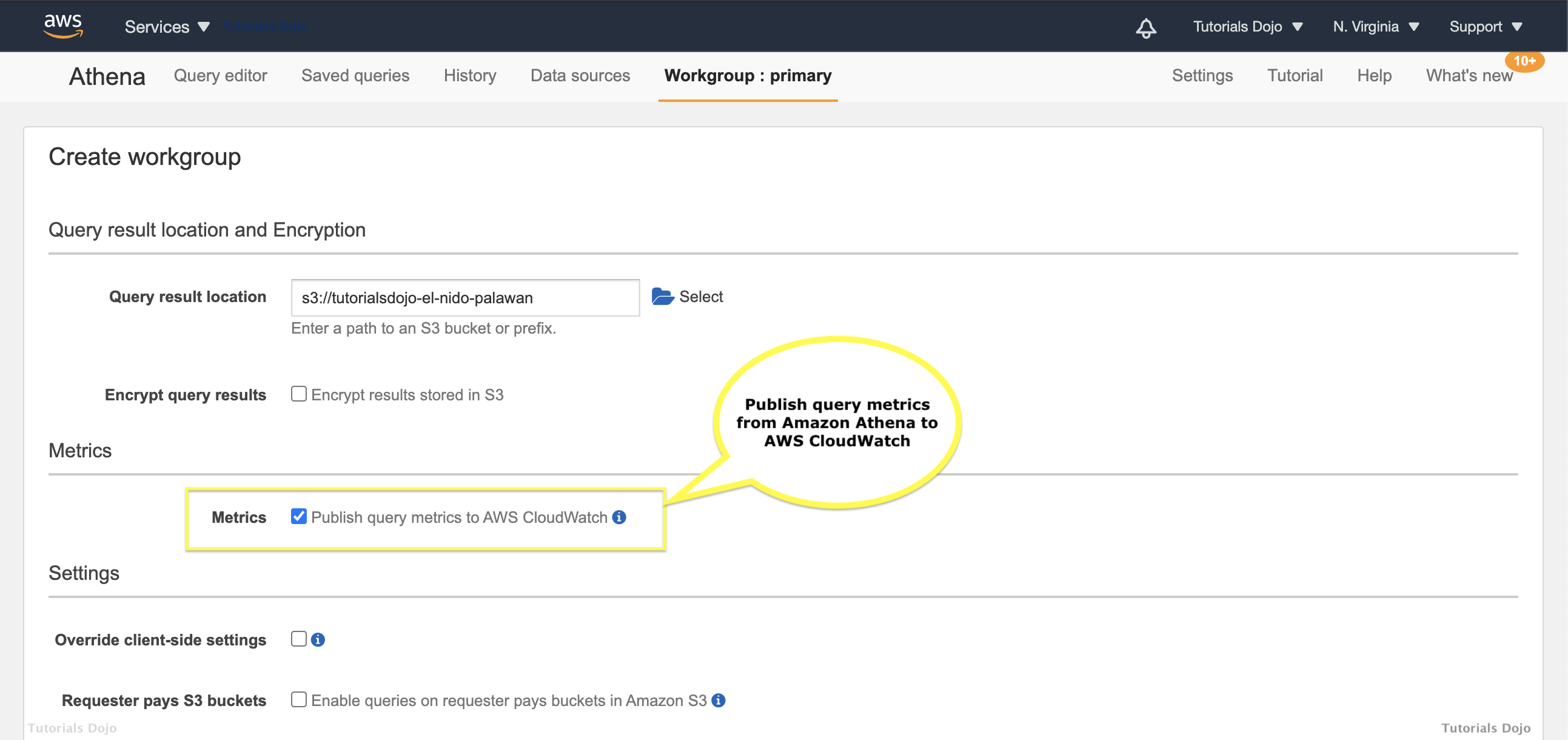
- Athena Workgroup enable the
Publish query metrics to AWS CloudWatch - KPL to publish metric level of DETAILED