
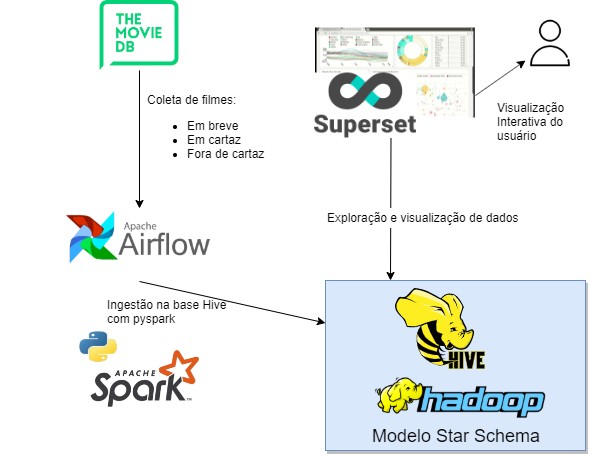
Project Diagram
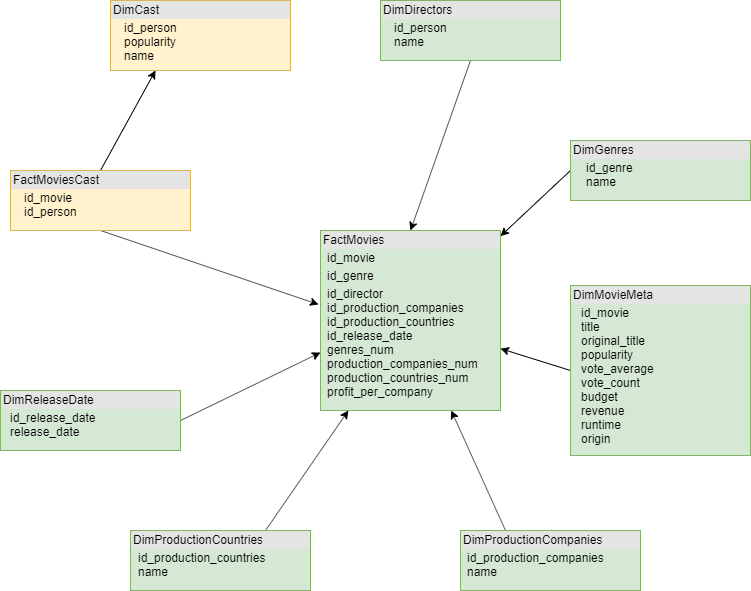
Database Schema
Stack used
- 1VM
- Cloudera Hortonworks Ambari
- HDFS
- Hive
- Superset
- JupyterLab
- Experiments
- Airflow
- Python
- PySpark
- Cloudera Hortonworks Ambari
Cloudera Hortonworks Ambari
Start Thrift ./usr/hdp/3.0.1.0-187/spark2/sbin/start-thriftserver.sh
Reset Ambari Admin Password ambari-admin-password-reset
Airflow
https://airflow.apache.org/installation.html https://airflow.apache.org/start.html
yum -y install python36 python36-pip python36-devel
export AIRFLOW_HOME=~/airflow
# install from pypi using pip
pip install apache-airflow
# initialize the database
airflow initdb
# start the web server, default port is 8080
airflow webserver -p 8080
# start the scheduler
airflow scheduler
# visit localhost:8080 in the browser and enable the example dag in the home page
or docker
docker rm -f airflow1
docker run -dit --name airflow1 -p 8124:8080 \
--network cda \
-v /root/airflow-dags:/root/airflow/dags \
-v /root/airflow-scripts:/scripts \
-v /root/airflow-scratch:/scratch \
airflow1
airflow scheduler
Spark
Install
yum -y install wget
#export SPARK_URL=http://ftp.unicamp.br/pub/apache/spark/spark-2.4.3/spark-2.4.3-bin-hadoop2.7.tgz
export SPARK_URL=http://ftp.unicamp.br/pub/apache/spark/spark-2.4.4/spark-2.4.4-bin-hadoop2.7.tgz
export SPARK_HOME=/opt/spark
wget ${SPARK_URL} -O /tmp/spark.tgz
tar xzvf /tmp/spark.tgz -C /opt/ && rm -rf /tmp/spark.tgz && mv /opt/spark* /opt/spark
pip3 install pyspark findspark
yum -y install java-1.8.0-openjdk
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64/jre/"
cat <<EOF > /etc/profile.d/spark.sh
export SPARK_HOME=/opt/spark
export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.222.b10-1.el7_7.x86_64/jre/"
EOF
Hive
https://medium.com/@o20021106/how-to-connect-to-remote-hive-cluster-with-pyspark-fabc04c42283
- Copy core-site.xml, hdfs-site.xml, hive-site.xml, hbase-site.xml, from your cluster running hive, and paste it to your spark’s /conf directory
- add any jar files to spark’s /jar directory.
- run pyspark
- Create a spark session and make sure to enable hive support.
wget /assets/files/0-35ynhUx_hive-site.xml
wget /assets/files/0-35ynhUx_core-site.xml
wget /assets/files/0-35ynhUx_hdfs-site.xml
wget http://coreto1:8081/download/codimd/71f4d5e87b4c4adfa32a0de1b11f5787.jar/hive-jdbc-standalone.jar
-O /opt/spark/jars/hive-jdbc-standalone.jar
PySpark
from pyspark import SparkConf
from pyspark.sql import SparkSession
from pyspark.sql import Row
spark = SparkSession \
.builder \
.appName("Python Spark SQL Hive integration example") \
.enableHiveSupport() \
.getOrCreate()
spark.sql("show databases").show()
SuperSet
Centos
yum -y install mariadb-devel
pip3 install mysqlclient
yum install -y cyrus-sasl-plain cyrus-sasl-devel cyrus-sasl-gssapi
pip3 install pyhive[hive]
Ubuntu apt install -y libsasl2-dev
Install superset 0.34.1
export LC_ALL=en_US.utf-8
export LANG=en_US.utf-8
yum -y install python36 python36-pip python36-devel gcc gcc-c++
Connect to Hive hive://hive@localhost:10016/movies 
Results
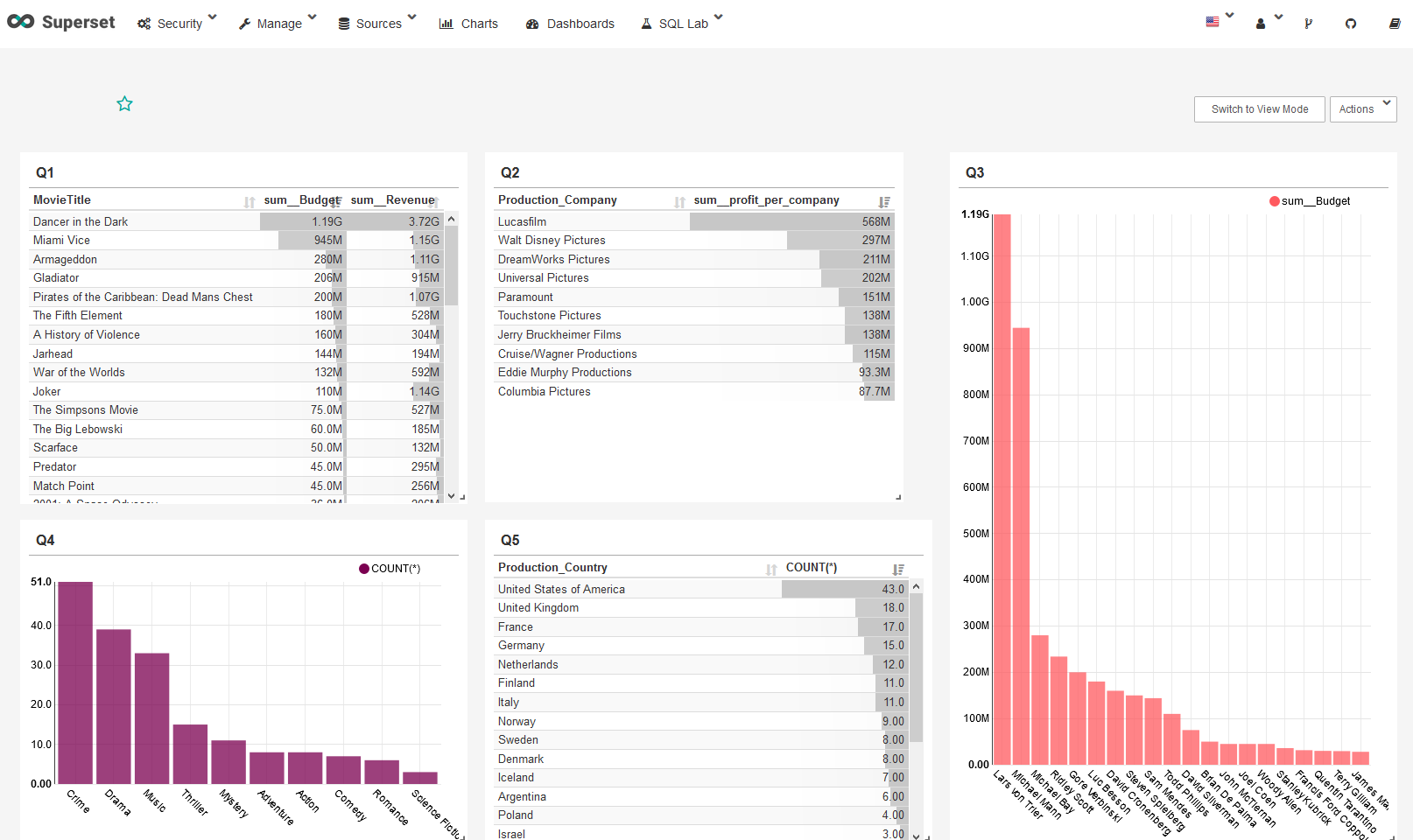
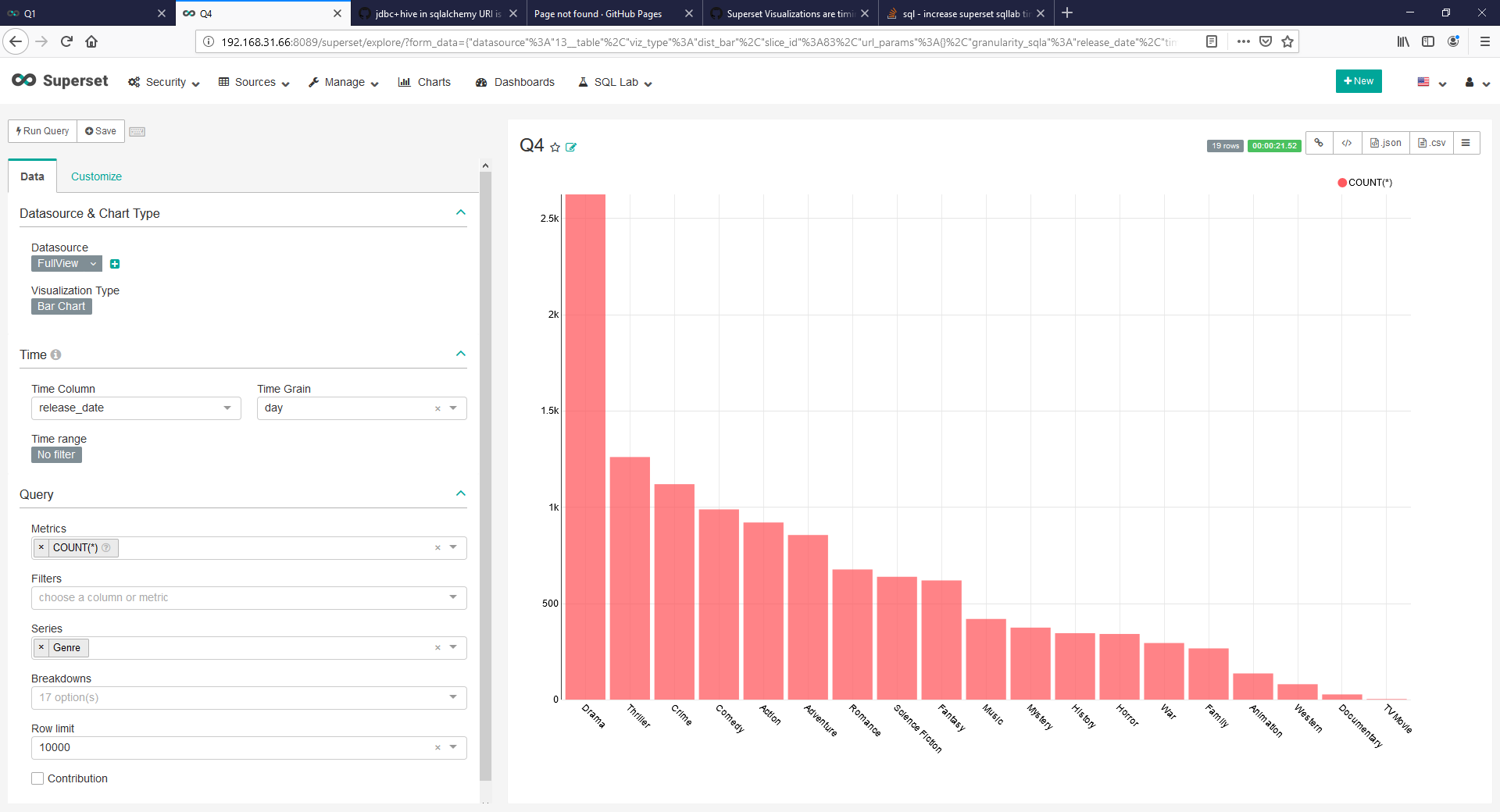

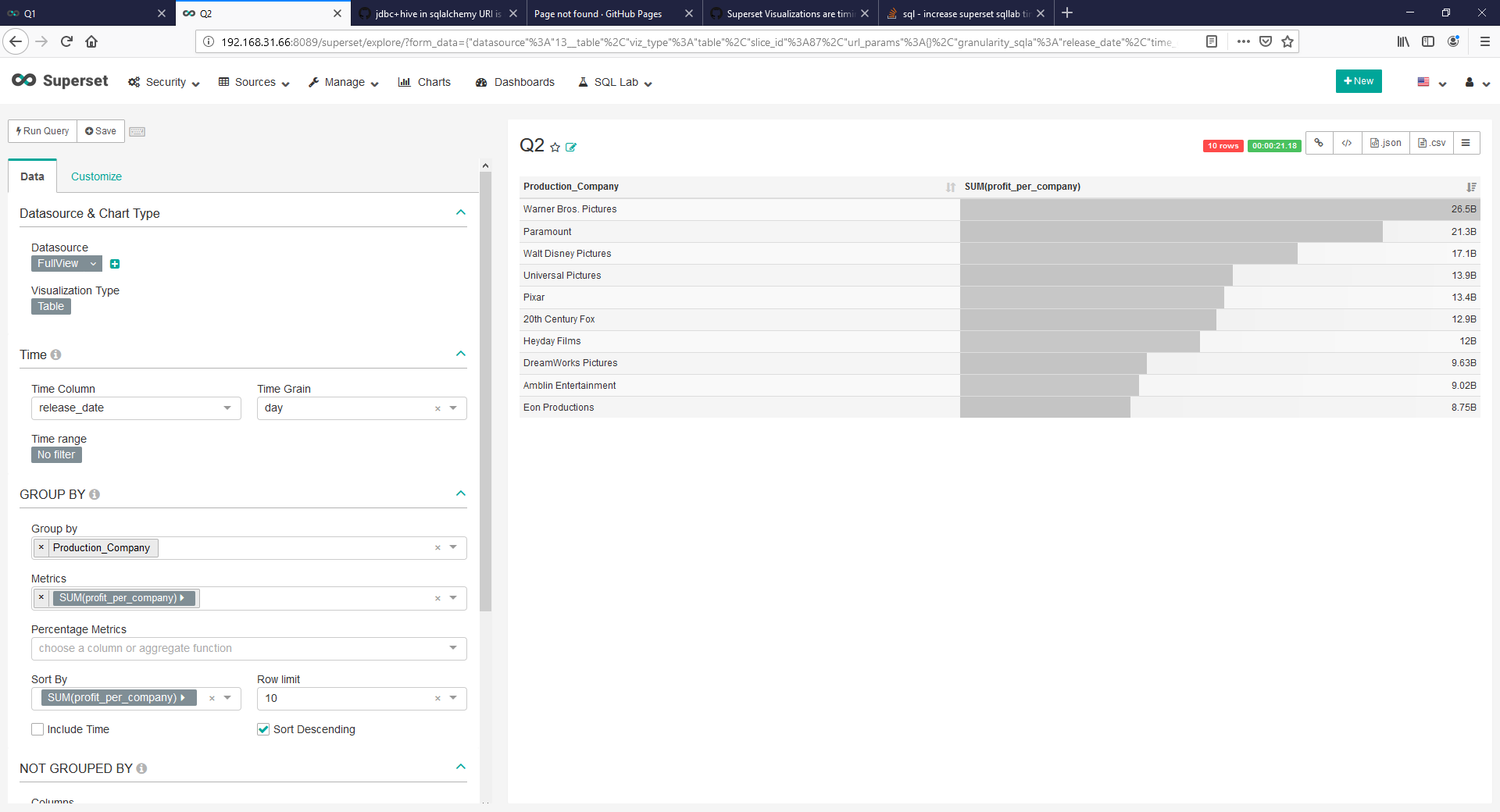
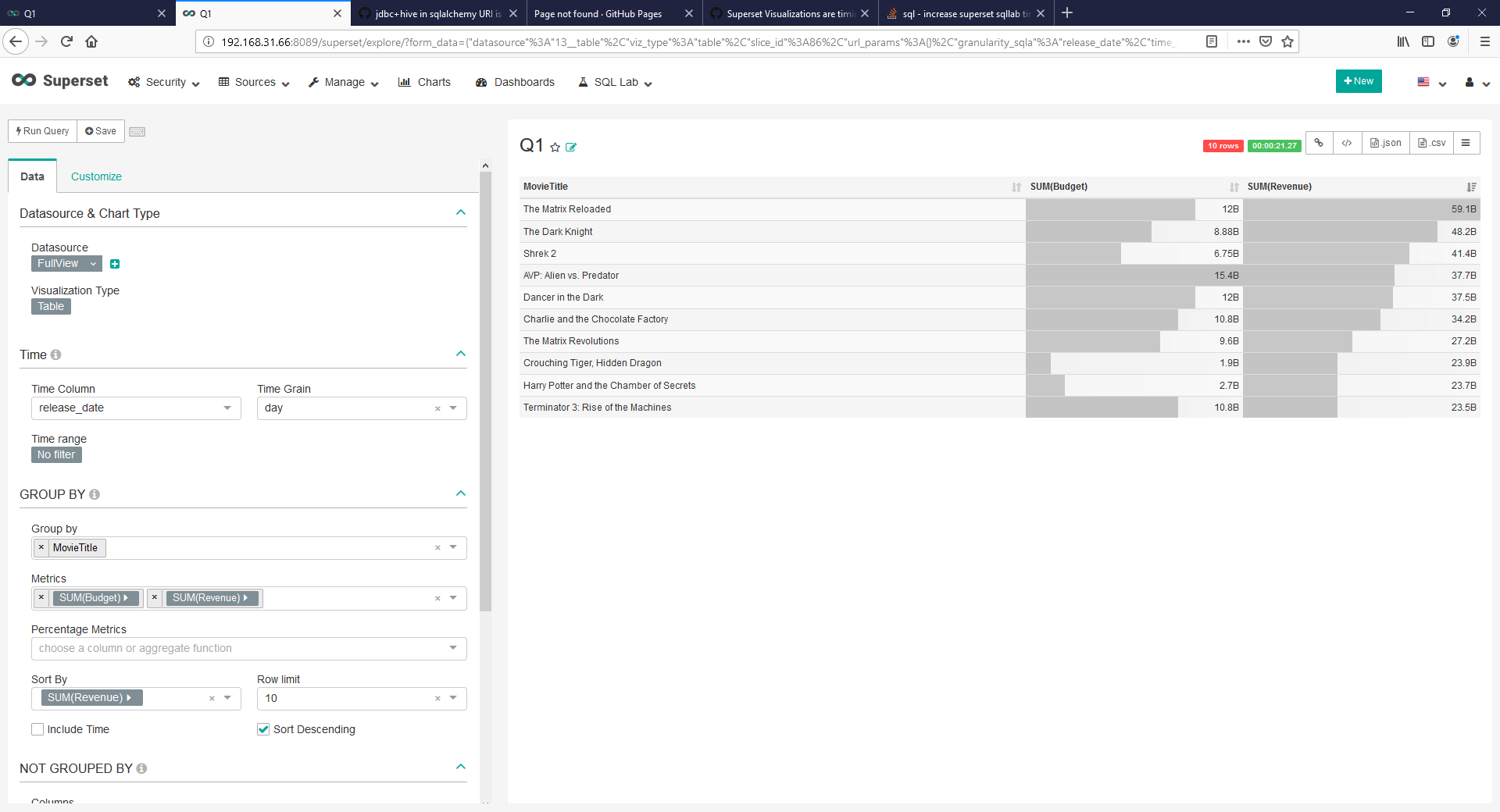
Known Caveats
Can’t sync spark to hive
https://community.cloudera.com/t5/Support-Questions/Spark2-shell-is-not-displaying-all-Hive-databases-only/td-p/193774
On Spark 2 and HDP 3.x . Edit file “/usr/hdp/3.1.4.0-315/spark2/conf/hive-site.xml”
Remove property below:
<property>
<name>metastore.catalog.default</name>
<value>spark</value>
</property>
Hive managed table doesn’t work in with non transactional in hive 3
https://community.cloudera.com/t5/Support-Questions/Hive-managed-table-doesn-t-work-in-with-non-transactional-in/td-p/237514 https://xgkfq28377.i.lithium.com/t5/image/serverpage/image-id/14232i8E84A1CF23E989AB/image-dimensions/1000?v=1.0&px=-1

SQL Lab query indefinitely in PENDING #4733
https://github.com/apache/incubator-superset/issues/4733
Point to spark2 hiveserver port 10016