
CDP Certification Program
https://www.cloudera.com/about/training/certification.html
- CDP Generalist
- CDP Administrator - Private Cloud Base
- https://www.cloudera.com/about/training/certification/cdp-adminpvc-exam-cdp-2001.html
- Planned exams
- CDP Certified Administrator - Public Cloud
- CDP Certified Data Developer
- CDP Certified Data Analyst

- https://medium.com/@nmani.1191/piece-of-insight-for-cloudera-certified-associate-spark-hadoop-developer-cca175-aacb20cc84b3
- https://www.udemy.com/course/cca-175-spark-and-hadoop-developer-python-pyspark/
- https://www.udemy.com/course/cca-175-spark-and-hadoop-developer-certification-scala/
- https://www.udemy.com/course/cca-175-exam-prep-qs-pt-a-with-spark-24-hadoop-cluster-vm/
- https://www.udemy.com/course/cca175-exam-preparation-series-part-b-with-vm/
- https://www.udemy.com/course/cca-175-spark-certification-practice-tests-python-2020-r/
- https://medium.com/@nmani.1191/piece-of-insight-for-cloudera-certified-associate-spark-hadoop-developer-cca175-aacb20cc84b3
https://www.cloudera.com/about/training/certification/cdp-generalist-exam-cdp-0011.html
- Cloudera Essentials for CDP
- CDP Private Cloud Fundamentals
- CDP Private Cloud Fundamentals - Cloudera, IBM, Red Hat
- https://www.cloudera.com/about/training.html#?fq=training%3Acomplimentary%2Ffree
- Cloudera Essentials for CDP
- pdf file.pdf


- Test your learning: Cloudera Data Platform Overview



- Role of Cloudera Runtime in CDP?
- Cloudera Runtime is the distribution package of open source software, combining the best open source software from CDH and HDP. which provides the foundation for all CDP deployments.
- CDP Public Cloud differs in some ways from our older distributions, CDH and HDP. Which two of the following indicate some ways in which CDP Public Cloud differs from these other distributions?
- CDP Public Cloud emphasizes the use of the cloud provider’s object store, such as S3 on Amazon Web Services or ADLS Gen 2 on Microsoft Azure, for data storage.
- CDP Public Cloud prefers to separate data storage and compute, whereas CDH and HDP performed these tasks on the same node.
- CDP Private Cloud Fundamentals
- Introduction to Cloudera Machine Learning
- Introduction to Cloudera Data Warehouse
- CDP Private Cloud Fundamentals - Cloudera, IBM, Red Hat
- Cloudera Essentials for CDP


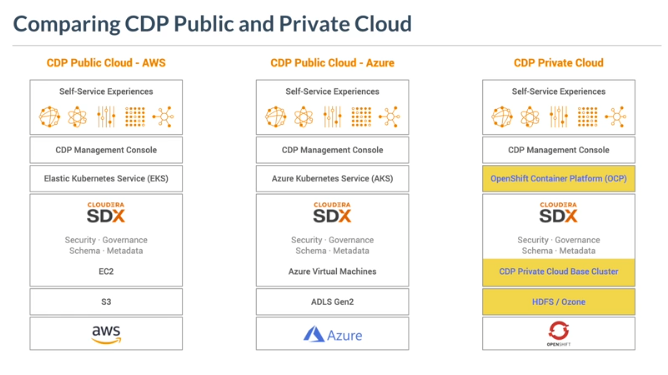
- (25%/15) Describe function of the main components of CDP architecture
- HDFS
- The HDFS is a block-structured filesystem where individual files are broken into multiple smaller chunks of a fixed size and stored across Hadoop clusters. The HDFS uses low-cost hardware to store large datasets. It supports high streaming read performance, but doesn’t advocate frequent updates on the file. It is based on the concept of “write once and read many times.”
- Ozone
- Ozone is a scalable, redundant, and distributed object store for Hadoop. Apart from scaling to billions of objects of varying sizes, Ozone can function effectively in containerized environments such as Kubernetes and YARN.
- Hive
- Original from Facebook.
- The Apache Hive ™ data warehouse software facilitates reading, writing, and managing large datasets residing in distributed storage using SQL. Structure can be projected onto data already in storage. A command line tool and JDBC driver are provided to connect users to Hive.
- Hue
- HUE (Hadoop User Experience)
- a web based workbench for Hadoop
- YARN
- Yet Another Resource Negociator
- YARN is a resource-allocation-based framework that manages cluster resources and supports a wide variety of applications that can share the resources side by side and run parallel. The YARN is a core component of Hadoop. It interacts with computing resources on behalf of the application and allocates resources based on application needs.
- HPC scheduler vs YARN: https://www.admin-magazine.com/HPC/Articles/The-New-Hadoop
- Running OpenMPI under YARN. MR+
- https://www.open-mpi.org/video/mrplus/Greenplum_RalphCastain-2up.pdf
- TPCH (50G 100G 256G) Hive benchmark
- Movie’s Histogram (30G)
- Rating’s Histogram (30G)
- wordcount (wikipedia 150G)
- Inverted-index (wikipedia 150G)
- https://www.open-mpi.org/video/mrplus/Greenplum_RalphCastain-2up.pdf
- Running OpenMPI under YARN. MR+
- Spark
- A unified engine designed for large-scale distributed data processing, on premises in data centers or in the cloud.
- Spark provides in-memory storage for intermediate computations, makint it much faster than Hadoop MapReduce. It incorporates libraries with composable APIs for machine learning (MLlib), SQL for interactive queries (Spark SQL), stream processing (Structured Streaming) for interacting with real-time data, and graph processing (GraphX).
- Impala
- Impala is a massively parallel processing (MPP) SQL engine designed and built from the ground up to run on Hadoop platforms. Impala provides fast, low-latency response times appropriate for business intelligence applications and ad hoc data analysis. Impala’s performance matches, and in most cases, surpasses commercial MPP engines.
- Impala started out as a project within Cloudera.
- It was donated to the Apache Software Foundation and accepted into the Apache incubator on December 2, 2015.
- Prior to joining Cloudera, Impala’s architect and tech lead, Marcel Kornacker, was a software engineer at Google who led the development of the distributed query engine of Google’s F1 Project,ii a distributed relational database system used to support Google’s highly critical and massively popular AdWords business,iii Cloudera released a beta version of Impala in October of 2012 and announced its general availability in May of 2013.
- Oozie
- Apache Oozie is a workflow scheduler for Hadoop. It is a system which runs the workflow of dependent jobs. Here, users are permitted to create Directed Acyclic Graphs of workflows, which can be run in parallel and sequentially in Hadoop.
- Kafka
- Original authors: linkekin
- Apache Kafka is a distributed event store and stream-processing platform. It is an open-source system developed by the Apache Software Foundation written in Java and Scala. The project aims to provide a unified, high-throughput, low-latency platform for handling real-time data feeds.
- NiFi
- Apache NiFi is a software project from the Apache Software Foundation designed to automate the flow of data between software systems. Leveraging the concept of Extract, transform, load, it is based on the “NiagaraFiles” software previously developed by the US National Security Agency (NSA), which is also the source of a part of its present name – NiFi. It was open-sourced as a part of NSA’s technology transfer program in 2014
- HBase
- Apache HBase began as a project by the company Powerset out of a need to process massive amounts of data for the purposes of natural-language search. Since 2010 it is a top-level Apache project.
- HBase is an open-source non-relational distributed database modeled after Google’s Bigtable and written in Java. It is developed as part of Apache Software Foundation’s Apache Hadoop project and runs on top of HDFS (Hadoop Distributed File System) or Alluxio, providing Bigtable-like capabilities for Hadoop.
- In the parlance of Eric Brewer’s CAP Theorem, HBase is a CP type system.

- HBase is not a direct replacement for a classic SQL database, however Apache Phoenix project provides a SQL layer for HBase as well as JDBC driver that can be integrated with various analytics and business intelligence applications.
- Phoenix
- Phoenix began as an internal project by the company salesforce.com out of a need to support a higher level, well understood, SQL language.
- Kudu
- The open source project to build Apache Kudu began as internal project at Cloudera.[4] The first version Apache Kudu 1.0 was released 19 September 2016.[5]
- Kudu vs HBase
- Kudu is for structured data whereas HBase is for schemaless data.
- HDFS
- (20%/12) Describe and compare security features of CDP Public Cloud and CDP Private Cloud Base
- Shared Data Experience (SDX)
- Data access and control layer that provides consistent security and governance for all applications running within CDP, in all locations, both on-premises and in the cloud.
- Control Plane Also provides a cmdline and APIs to allow admins to automate common tasks.
- Data Catalog
- Helps them to understand, manager, and secure data assets
- Replication Manager
- Used to replicate migrate data and metadata between environments
- Workload Manager
- Used to analyze, troubleshoot, and optimize workloads
- Management Console
- Provides a single pane of glass for managing all clusters
- Data Catalog
- CDP Public integration with cloud SSO
- CDP Private Cloud integration with LDAP, Kerberos
- CDP Private Cloud Base HDFS transparent encryption
- https://docs.cloudera.com/cdp-private-cloud-base/7.1.6/security-encrypting-data-at-rest/topics/cm-security-hdfs-te.html
- https://blog.cloudera.com/new-in-cdh-5-3-transparent-encryption-in-hdfs/
- CDP Public Cloud security features of cloud providers storage security
- Describe how CDP protects protects data on the O/S file system i.e. (Cloudera navigator encrypt)
- SSL/TLS implementation
- Kerberos authentication
- Shared Data Experience (SDX)
- (15%/9) List and describe 5 analytic experiences
- Cloudera Data Engineering
- Cloudera Data Warehouse
- Cloudera Operational Database
- Cloudera Machine Learning
- Cloudera DataFlow
- Nifi
- Describe requirements to deploy CDP Public cloud on major cloud infrastructure providers
- AWS
- Azure
- GCP
- (10%/6) Describe local system requirements to deploy CDP Private Cloud Base
- (5%/3) Describe the use and major functions of Cloudera Manager
- (5%/3) Describe the use and major functions of Workload XM
- https://www.cloudera.com/content/dam/www/marketing/resources/webinars/introducing-workload-xm-recorded-webinar.png.landing.html
- Workload Experience Manager (XM) gives you the visibility necessary to efficiently migrate, analyze, optimize, and scale workloads running in a modern data warehouse. In this recorded webinar we discuss common challenges running at scale with modern data warehouse, benefits of end-to-end visibility into workload lifecycles, overview of Workload XM and live demo, real-life customer before/after scenarios, and what’s next for Workload XM.
- https://www.cloudera.com/content/dam/www/marketing/resources/webinars/introducing-workload-xm-recorded-webinar.png.landing.html
- (5%/3) Describe the use and major functions of Replication Manager
- Other Skills & Knowledge
- Cloud providers
- AWS
- Azure
- GCP
- Linux
- Network security e.g. SSL/TLS
- User authentication, authorization e.g. kerberos, LDAP, SQL, etc.
Cloudera CDP-0011 Generalist Certification







Top Highly Paying Data Engineering Certifications in 2021
https://techninjahere.medium.com/top-highly-paying-data-engineering-certifications-9068b6a19a44
